# A tibble: 336,776 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 533 529 4 850 830
3 2013 1 1 542 540 2 923 850
4 2013 1 1 544 545 -1 1004 1022
5 2013 1 1 554 600 -6 812 837
6 2013 1 1 554 558 -4 740 728
7 2013 1 1 555 600 -5 913 854
8 2013 1 1 557 600 -3 709 723
9 2013 1 1 557 600 -3 838 846
10 2013 1 1 558 600 -2 753 745
# ℹ 336,766 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>8 Daten transformieren
Neben ggplot2 ist dplyr ein sehr wichtiger Bestandteil der tidyverse Paketsammlung. Die Funktionen des Pakets dplyr dienen dazu Daten zu analysieren und aufzuarbeiten, das heißt in eine geeignete Form zu bekommen um diese entweder grafisch oder tabellarisch darzustellen oder aus ihnen Kenngrößen zu berechnen. Wir wollen in diesem Kapitel die Funktionsweise der in Tabelle 8.1 aufgeführen Funktionen anhand diverser Beispiele erläutern.
dplyr
| Kategorie | Funktion | Bedeutung |
|---|---|---|
| Zeilen | filter() |
Beobachtungen (Zeilen) nach vorgegebenen Kriterien filtern |
arrange() |
Beobachtungen (Zeilen) sortieren | |
| Spalten | select() |
Merkmale (Spalten) auswählen |
mutate() |
Merkmale (Spalten) (aus ggf. bereits vorhandenen) neu erstellen bzw. vorhandene ändern | |
rename() |
Umbenennen von Merkmalen (Spalten) | |
relocate() |
Ändern der Stellung eines Merkmals (Spalte) | |
| Gruppierungen | summarise() |
Anzahlen und statistische Kenngrößen berechnen |
group_by() |
Gruppierungen nach Faktorstufen vornehmen, wird oft in Verbindung mit summarise verwendet |
|
slice_min() |
Zeigt n (gruppierte) Beobachtungen, wobei die kleinsten bezüglich eines Merkmals angezeigt werden |
|
slice_max() |
Zeigt n (gruppierte) Beobachtungen, wobei die größten bezüglich eines Merkmals angezeigt werden |
|
slice_head() |
Zeigt n (gruppierte) Beobachtungen, wobei die ersten der Datentabelle angezeigt werden |
|
slice_tail() |
Zeigt n (gruppierte) Beobachtungen, wobei die letzten der Datentabelle angezeigt werden |
|
slice_sample() |
Zeigt n zufällige (gruppierte) Beobachtungen |
8.1 Der Datensatz nycflights
Um die obigen Funktionen zu verstehen werden wir den Datensatz flights aus dem Paket nycflights13 nutzen. Der Datensatz enthält alle Flüge, die im jahr 2013 von New Yorker Flughäfen abgeflogen sind. Insgesamt hat dieser Datensatz 19 Merkmale und 336,776 Beobachtungen. Eine detaillierte Übersicht zu den Merkmalen gibt es in der Hilfe.
In einer Datentabelle, die im Tibble-Format abgespeichter ist, kann man den Kurznamen des jeweiligen Datentypen unterhalb des Merkmalnamens sehen. Eine kurze Überischt über eine Datentabelle (Merkmalsnamen, Datentypen, Dimensionen und die ersten Einträge) enhält man auch mit dem Befehl glimpse (aus aus dem Paket dplyr).
glimpse(flights)Rows: 336,776
Columns: 19
$ year <int> 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2…
$ month <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ day <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ dep_time <int> 517, 533, 542, 544, 554, 554, 555, 557, 557, 558, 558, …
$ sched_dep_time <int> 515, 529, 540, 545, 600, 558, 600, 600, 600, 600, 600, …
$ dep_delay <dbl> 2, 4, 2, -1, -6, -4, -5, -3, -3, -2, -2, -2, -2, -2, -1…
$ arr_time <int> 830, 850, 923, 1004, 812, 740, 913, 709, 838, 753, 849,…
$ sched_arr_time <int> 819, 830, 850, 1022, 837, 728, 854, 723, 846, 745, 851,…
$ arr_delay <dbl> 11, 20, 33, -18, -25, 12, 19, -14, -8, 8, -2, -3, 7, -1…
$ carrier <chr> "UA", "UA", "AA", "B6", "DL", "UA", "B6", "EV", "B6", "…
$ flight <int> 1545, 1714, 1141, 725, 461, 1696, 507, 5708, 79, 301, 4…
$ tailnum <chr> "N14228", "N24211", "N619AA", "N804JB", "N668DN", "N394…
$ origin <chr> "EWR", "LGA", "JFK", "JFK", "LGA", "EWR", "EWR", "LGA",…
$ dest <chr> "IAH", "IAH", "MIA", "BQN", "ATL", "ORD", "FLL", "IAD",…
$ air_time <dbl> 227, 227, 160, 183, 116, 150, 158, 53, 140, 138, 149, 1…
$ distance <dbl> 1400, 1416, 1089, 1576, 762, 719, 1065, 229, 944, 733, …
$ hour <dbl> 5, 5, 5, 5, 6, 5, 6, 6, 6, 6, 6, 6, 6, 6, 6, 5, 6, 6, 6…
$ minute <dbl> 15, 29, 40, 45, 0, 58, 0, 0, 0, 0, 0, 0, 0, 0, 0, 59, 0…
$ time_hour <dttm> 2013-01-01 05:00:00, 2013-01-01 05:00:00, 2013-01-01 0…Man sieht damit auf den ersten Blick die Dimensionen der Datentabelle, sowie alle Merkmalsnamen und Merkmalstypen sowie die ersten Einträge der jeweiligen Merkmale.
8.2 Datentypen
Wir haben in den letzten Kapiteln bereits die (atomaren) Datentypen logical, integer, double und character kennengelernt. An der Datentabelle nycflights sehen wir, dass es noch weitere Typen gibt. Wir wollen in diesem Kapitel ein wenig Struktur in die Datentypen bringen und die atomaren Datentypen von den zusammengestzten Daten, die wir auch Datenstrukturen nennen abgrenzen.
8.2.1 Atomare Datentypen
In der Tabelle 8.2 sind die sechs atomaren Datentypen mit den Kurznamen, wie sie in einem Tibble auftauchen, sowie Beispielen aufgeführt.
raw ist nur der Vollständigkeit aufgeführt und wird im Wesentlichen nicht benötigt. Der raw-Typ sind nicht interpretierte Speicherwerte.
| Name | Kurzname | Erklärung | Beispiele |
|---|---|---|---|
logical |
<lgl> |
Logischer Ausdruck |
TRUE, T, FALSE, F
|
integer |
<int> |
ganze Zahlen |
2, 4L, -7
|
double |
<dbl> |
Fließkommazahlen |
1.2, pi, 3e-7
|
complex |
<cpl> |
Komplexe Zahlen |
2+3i, 0-1i
|
character |
<chr> |
Zeichenketten |
"Haus", "K2", "110_112"
|
raw |
<raw> |
Rohdaten (Byte-Darstellung) (selten!) | as.raw(255) |
Vektoren sind die zugrunde liegende Strukturform in der Daten
Mit der Funktion typeof() können wir bei einem R-Objekt den Datentyp herausfinden.
8.2.2 Kategoriale und geordnete Typen
(Geordnete) Faktoren benötigt man immer dann, wenn es für ein Merkmal endlich viele bekannte und feste Ausprägungen, den Levels, gibt. Wir weden uns in Kapitel 12 noch damit beschäftigen.
| Name | Kurzname | Erklärung | Beispiele |
|---|---|---|---|
factor |
<fct> |
Kategoriale Merkmale mit festen Levels |
"rot", "blau", "grün"
|
ordered |
<ord> |
Geordnete kategoriale Merkmale | "klein" < "mittel" < "groß" |
8.2.3 Zeitbezogene Typen
| Name | Kurzname | Erklärung | Beispiele |
|---|---|---|---|
📅 date
|
<date> |
Datum (ohne Zeit) | as.Date("2023-09-22") |
⏰ datetime
|
<dttm> |
Datum und Uhrzeit (POSIXct) | asPOSIXct("2025-10-21 11:20:00") |
⏳ difftime
|
<difftime> |
Zeitdifferenz zwischen zwei Daten/Zeitpunkten | difftime(Sys.time(), start) |
📈 ts (time series)
|
<ts> |
Zeitreihenobjekt mit fester Frequenz | ts(1:10, start=2020, freq=4) |
8.2.4 Zusammengesetzte Datenstrukturen
| Name | Kurzname | Erklärung | Beispiele |
|---|---|---|---|
📚 list
|
<list> |
Sammlung beliebiger Objekte (heterogen) | list(1, "a", TRUE) |
🧮 matrix
|
<mtrx> |
2D-Array gleichen Datentyps | matrix(1:6, ncol=2) |
🧊 array
|
<arr> |
Mehrdimensionale Datenstruktur gleichen Typs | array(1:8, dim=c(2,2,2)) |
📊 data.frame
|
<df> |
Tabellarische Struktur mit Spalten unterschiedlichen Typs | data.frame(x=1:3, y=c("a","b","c")) |
📘 tibble
|
<tbl> |
Moderne Variante von data.frame (tidyverse) |
tibble(x=1:3, y=c("a","b","c")) |
8.3 Die Funktion filter()
Beobachtungen (Zeilen) filtern mit filter()
filter(flights, month == 10, day == 3) oder in der praktischen Pipe-Schreibweise, die wir ab nun immer verwenden werden:
flights |> filter(month == 10, day == 3)# A tibble: 995 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 10 3 453 500 -7 636 648
2 2013 10 3 512 517 -5 739 757
3 2013 10 3 541 545 -4 826 855
4 2013 10 3 541 545 -4 920 933
5 2013 10 3 546 545 1 822 827
6 2013 10 3 546 550 -4 917 932
7 2013 10 3 550 600 -10 646 708
8 2013 10 3 550 600 -10 844 858
9 2013 10 3 552 600 -8 651 659
10 2013 10 3 552 600 -8 656 711
# ℹ 985 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>- Mit der Funktion
filter()werden Beobachtungen (Zeilen) nach gewissen Auswahlkriterien gefiltert. - Im Beispiel oben werden alle Beobachtungen, bei denen
monthgleich10unddaygleich3ist, gefiltert, also alle Flüge, die am 03. Oktober stattgefunden haben.
Im Kapitel 5.5 wurde bereits die Syntax des Pipe-Operators |> eingeführt. Im Zusammenhang mit den Funktionen des Pakets dplyr bietet sich diese Syntax besonders an: das erste Argument der dplyr-Funktionen ist eine Datentabelle und auch das Ergebnis einer dplyr-Funktion ist wieder eine Datentabelle.
8.3.1 Zuweisung und Ausgabe nach filter()
# Zuweisung ohne Ausgabe der Datentabelle
jan01 <- flights |> filter(month == 1, day == 1)
# Zuweisung mit Ausgabe der Datentabelle: () um die Zuweisung setzen:
(jul14 <- flights |> filter(month == 7, day == 14))# A tibble: 931 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 7 14 6 2359 7 355 344
2 2013 7 14 112 2359 73 447 340
3 2013 7 14 456 500 -4 635 640
4 2013 7 14 525 525 0 737 756
5 2013 7 14 537 540 -3 828 840
6 2013 7 14 542 515 27 712 720
7 2013 7 14 549 600 -11 654 715
8 2013 7 14 551 600 -9 646 655
9 2013 7 14 553 600 -7 834 851
10 2013 7 14 554 600 -6 725 752
# ℹ 921 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>8.3.2 Vergleiche
| Symbol | Bedeutung |
|---|---|
== |
gleich |
!= |
ungleich |
> |
größer als |
>= |
größer als oder gleich |
< |
kleiner als |
<= |
kleiner als oder gleich |
Um filtern zu können, ist es wichtig, die Vergleichsoperatoren zu verstehen. Das Ergebnis eines Vergleichs ist ein logischer Wert, das heißt TRUE, FALSE oder aber NA, was für Not Available steht.
Beispiele
3 >= 2[1] TRUE0 > -3:2 # Recycling[1] TRUE TRUE TRUE FALSE FALSE FALSE5 != c(2, 5, NA) # Recycling[1] TRUE FALSE NASchon einfache Rechnungen können beim Vergleich von Fließkommazahlen mit == zu Fehlern führen:
1.7 + 2.4 - 3.1 == 1[1] FALSEDaher sollten wir immer darauf achten, den Vergleichsoperator == bei Fließkommazahlen zu vermeiden und statt dessen die Funktion near() (auch aus dem Paket dplyr) zu verwenden.
Auch logische Vektoren oder Zeichenketten können verglichen werden.
8.3.3 Logische Operatoren
Oft sind wir in der Situation, dass man Beobachtungen nach mehr als einem Merkmal filtern möchte: im ersten Beispiel wurde das Datum nach Monat und nach einem Tag gefiltert. Mit Hilfe der Methoden der Aussagenlogik, die in Kapitel 18 behandelt wird, kann man auch kompliziertere Auswahlen treffen.
Erklärung an Beispielen:
Die Venn-Diagramme sind in gewissen Sinn allgemeingültig und auf alle Fälle anwendbar, wobei Segmente (es gibt insgesamt vier) auch leer sein könnten. Die rechteckige Box repräsentiert alle Beobachtungen; der Kreis in dem x steht repräsentiert alle Beobachtungen bei dem ein Merkmal die Ausprägung x hat, und analog ist der Kreis mit dem y ein (ggf. anderes) Merkmal, bei dem die Ausprägung y ist.
Rechts neben den Venn-Diagrammen ist ein jeweils ein Beispiel zu finden: der Datensatz flights enthält alle Beobachtung (das Rechteck, die Grundmenge), x sind alle Flüge, die an einem 3. eines Monats geflogen sind (day == 3) und y sind alle Flüge, die im 10. Monat geflogen sind (month == 10).
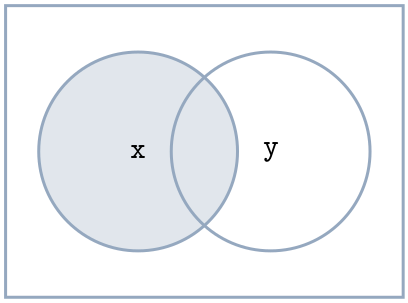

!x (\neg x)
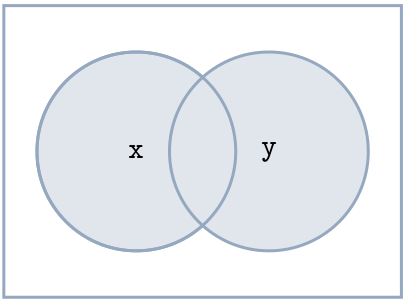
x|y (x \vee y)
Disjunktion (ODER):
flights |>
filter(day == 3 | month == 10) 
x&y (x \wedge y)
- Man sieht die Wirkung der boolschen Operatoren
&(UND, Konjunktion),|(ODER, Disjunktion), sowie!(NICHT, Negation). - Die Negation bindet stärker als die Konjunktion und diese wiederum stärker als die Disjunktion. Deswegen müssen ggf. runde Klammern gesetzt werden.
Beispiele:
Der folgenden beiden Ausdrücke filtern alle Flüge, die im November oder Dezember stattgefunden haben:
flights |> filter(month == 11 | month == 12)# A tibble: 55,403 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 11 1 5 2359 6 352 345
2 2013 11 1 35 2250 105 123 2356
3 2013 11 1 455 500 -5 641 651
4 2013 11 1 539 545 -6 856 827
5 2013 11 1 542 545 -3 831 855
6 2013 11 1 549 600 -11 912 923
7 2013 11 1 550 600 -10 705 659
8 2013 11 1 554 600 -6 659 701
9 2013 11 1 554 600 -6 826 827
10 2013 11 1 554 600 -6 749 751
# ℹ 55,393 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm># A tibble: 55,403 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 11 1 5 2359 6 352 345
2 2013 11 1 35 2250 105 123 2356
3 2013 11 1 455 500 -5 641 651
4 2013 11 1 539 545 -6 856 827
5 2013 11 1 542 545 -3 831 855
6 2013 11 1 549 600 -11 912 923
7 2013 11 1 550 600 -10 705 659
8 2013 11 1 554 600 -6 659 701
9 2013 11 1 554 600 -6 826 827
10 2013 11 1 554 600 -6 749 751
# ℹ 55,393 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>Der zweite Ausdruck ist eine praktische Abkürzung:
x %in% yliefert einen Vektor aus Wahrheitswerten, dessen Einträge genau dannTRUEsind, wenn die entsprechendex-Komponente inyenthalten ist. Zusammen mit der Funktionfilter()werden dann die entsprechenden Beobachtungen gefiltert.-
Oft können komplizierte Ausdrücke durch die De Morganschen Regeln vereinfacht werden. Diese lauten:
!(x & y)ist das gleiche wie!x | !y!(x | y)ist das gleiche wie!x & !y
Diese drei Ausdrücke filtern alle Flüge, die weder bei der Ankunft noch beim Abflug mehr als zwei Stunden Verspätung hatten:
- Die Funktion
between()ist eine intuitive Abkürzung für zwei Ungleichungen. Die folgenden beiden Ausdrücke sind damit gleich:
Durch welche logischen Operationen kann der eingefärbte Teil ausgewählt werden?
Die Operatorrangfolge wurde bereits in Kapitel 5.1.3 besprochen. Allerdings sind wir bei den Beispielen nicht auf die logischen Verknüpfungen eingegangen.
TRUE | FALSE & FALSE[1] TRUE(TRUE | FALSE) & FALSE[1] FALSEIn diesem Beispiel kann man sehen, dass UND & stärker bindet als ODER |.
8.3.4 Fehlende Werte
- Anders als z.B. bei Excel-Tabellen, in denen Zellen leer sein können, gibt es in de R-Datentabellen keine Leereinträge.
- Statt dessen gibt es den Eintrag
NA(Not Available). - Mit der Funktion
is.na()kann nachNA-Einträgen gesucht werden. Die Funktion liefertTRUEfalls ein EintragNAist undFALSEfalls dies nicht der Fall ist. - Damit kann auch nach
NAWerten gefiltert werden, z.B.
(df <- tibble(x = c(2, 1, NA, 5, NA)))# A tibble: 5 × 1
x
<dbl>
1 2
2 1
3 NA
4 5
5 NA# A tibble: 3 × 1
x
<dbl>
1 NA
2 5
3 NAHier noch ein paar wichtige Beispiele, wie sich NA bei Vergleichen verhält.
8.4 Sortieren mit arrange()
Mit Hilfe der Funktion arrange() kann man Zeilen sortieren. Analog zu filter() kann arrange() mehrere Argumente (nach der Datentabelle) haben, wobei die Reihenfolge hierarchisch ist, das heißt es wird zuerst nach der ersten angegebenen Variablen sortiert, dann innerhalb dieser nach der zweiten usw.
Die Ordnung ist aufsteigend, möchte man eine absteigende Ordnung erreichen, so muss die Funktion
desc()genutzt werden.Fehlende Werte (
NA) werden in beiden Fällen ans Ende gesetzt.
Beispiel:
Im folgenden Beispiel wird zuerst absteiged nach Verspätung und dann aufsteigend nach Ziellughafen sortiert.
flights |> arrange(desc(dep_delay), dest)# A tibble: 336,776 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 9 641 900 1301 1242 1530
2 2013 6 15 1432 1935 1137 1607 2120
3 2013 1 10 1121 1635 1126 1239 1810
4 2013 9 20 1139 1845 1014 1457 2210
5 2013 7 22 845 1600 1005 1044 1815
6 2013 4 10 1100 1900 960 1342 2211
7 2013 3 17 2321 810 911 135 1020
8 2013 6 27 959 1900 899 1236 2226
9 2013 7 22 2257 759 898 121 1026
10 2013 12 5 756 1700 896 1058 2020
# ℹ 336,766 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>
8.5 Merkmale (Spalten) auswählen mit select()
- Insbesonders bei sehr großen Datentabellen mit ggf. hunderten Merkmalen ist es sinnvoll, die Anzahl der Merkmale zu reduzieren oder in eine besser geeignete Reihenfolge zu bringen.
- Dies geschieht mit dem Befehl
select(). - Neben explizitem Auflisten der Merkmalsnamen sind auch verkürzte Formen der folgenden Form möglich:
# alle Merkmale von year bis day:
flights |> select(year:day)# A tibble: 336,776 × 3
year month day
<int> <int> <int>
1 2013 1 1
2 2013 1 1
3 2013 1 1
4 2013 1 1
5 2013 1 1
6 2013 1 1
7 2013 1 1
8 2013 1 1
9 2013 1 1
10 2013 1 1
# ℹ 336,766 more rows# alle Merkmale außer die von year bis day:
flights |> select(-(year:day))# A tibble: 336,776 × 16
dep_time sched_dep_time dep_delay arr_time sched_arr_time arr_delay carrier
<int> <int> <dbl> <int> <int> <dbl> <chr>
1 517 515 2 830 819 11 UA
2 533 529 4 850 830 20 UA
3 542 540 2 923 850 33 AA
4 544 545 -1 1004 1022 -18 B6
5 554 600 -6 812 837 -25 DL
6 554 558 -4 740 728 12 UA
7 555 600 -5 913 854 19 B6
8 557 600 -3 709 723 -14 EV
9 557 600 -3 838 846 -8 B6
10 558 600 -2 753 745 8 AA
# ℹ 336,766 more rows
# ℹ 9 more variables: flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
# air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm># die Merkmale 1 bis 6 , 8 und 12 auswählen:
flights |> select(c(1:6, 8, 12))# A tibble: 336,776 × 8
year month day dep_time sched_dep_time dep_delay sched_arr_time tailnum
<int> <int> <int> <int> <int> <dbl> <int> <chr>
1 2013 1 1 517 515 2 819 N14228
2 2013 1 1 533 529 4 830 N24211
3 2013 1 1 542 540 2 850 N619AA
4 2013 1 1 544 545 -1 1022 N804JB
5 2013 1 1 554 600 -6 837 N668DN
6 2013 1 1 554 558 -4 728 N39463
7 2013 1 1 555 600 -5 854 N516JB
8 2013 1 1 557 600 -3 723 N829AS
9 2013 1 1 557 600 -3 846 N593JB
10 2013 1 1 558 600 -2 745 N3ALAA
# ℹ 336,766 more rowsflights |> select(year, month, day, dest)# A tibble: 336,776 × 4
year month day dest
<int> <int> <int> <chr>
1 2013 1 1 IAH
2 2013 1 1 IAH
3 2013 1 1 MIA
4 2013 1 1 BQN
5 2013 1 1 ATL
6 2013 1 1 ORD
7 2013 1 1 FLL
8 2013 1 1 IAD
9 2013 1 1 MCO
10 2013 1 1 ORD
# ℹ 336,766 more rows
8.5.1 Die tidyselect-Funktionen
Das Paket tidyselect, das nicht zusätzlich installiert oder geladen werden muss, stellt einige praktische Hilfsfunktionen zu Verfügung, die man innerhalb von select() nutzen kann um auf einfache Weise Merkmalsnamen zu selektieren, die ein bestimmtes Muster haben.
-
starts_with(): wählt alle Merkmale aus, die mit einer bestimmten Zeichenfolge beginnen
flights |> select(starts_with("dep_"),
starts_with("arr_"))# A tibble: 336,776 × 4
dep_time dep_delay arr_time arr_delay
<int> <dbl> <int> <dbl>
1 517 2 830 11
2 533 4 850 20
3 542 2 923 33
4 544 -1 1004 -18
5 554 -6 812 -25
6 554 -4 740 12
7 555 -5 913 19
8 557 -3 709 -14
9 557 -3 838 -8
10 558 -2 753 8
# ℹ 336,766 more rows-
ends_with(): wählt alle Merkmale aus, die mit einer bestimmten Zeichenfolge enden
flights |> select(ends_with("time"))# A tibble: 336,776 × 5
dep_time sched_dep_time arr_time sched_arr_time air_time
<int> <int> <int> <int> <dbl>
1 517 515 830 819 227
2 533 529 850 830 227
3 542 540 923 850 160
4 544 545 1004 1022 183
5 554 600 812 837 116
6 554 558 740 728 150
7 555 600 913 854 158
8 557 600 709 723 53
9 557 600 838 846 140
10 558 600 753 745 138
# ℹ 336,766 more rows-
contains(): wählt alle Merkmale, die eine bestimmte Zeichenkettenfolge enthalten, wobei es keine Rolle spielt, an welcher Stelle diese steht:
flights |> select(contains("time"))# A tibble: 336,776 × 6
dep_time sched_dep_time arr_time sched_arr_time air_time time_hour
<int> <int> <int> <int> <dbl> <dttm>
1 517 515 830 819 227 2013-01-01 05:00:00
2 533 529 850 830 227 2013-01-01 05:00:00
3 542 540 923 850 160 2013-01-01 05:00:00
4 544 545 1004 1022 183 2013-01-01 05:00:00
5 554 600 812 837 116 2013-01-01 06:00:00
6 554 558 740 728 150 2013-01-01 05:00:00
7 555 600 913 854 158 2013-01-01 06:00:00
8 557 600 709 723 53 2013-01-01 06:00:00
9 557 600 838 846 140 2013-01-01 06:00:00
10 558 600 753 745 138 2013-01-01 06:00:00
# ℹ 336,766 more rowsnum_range(): wählt nummerierte Merkmale aus, z.B. wählt das untere Beispiel aus dem unten erstellten Datensatz df die Merkmale x1 und x3 aus.
(df <- tibble(x1 = 1:3, x2 = 11:13,
x3 = 21:23, x4 = 31:33,
y1 = 22:24))# A tibble: 3 × 5
x1 x2 x3 x4 y1
<int> <int> <int> <int> <int>
1 1 11 21 31 22
2 2 12 22 32 23
3 3 13 23 33 24df |> select(num_range("x", c(1,3)))# A tibble: 3 × 2
x1 x3
<int> <int>
1 1 21
2 2 22
3 3 23Bemerkung
Es ist immer darauf zu achten, dass der String innerhalb der Funktion in Anführungszeichen steht!
8.6 Die Funktion mutate()
8.6.1 Neue Merkmale (Spalten) erstellen
- Mit der Funktion
mutate()können neue Merkmale zu einem Datensatz hinzugefügt werden, die oft aus existierenden Merkmalen gewonnen werden. - Im unteren Beispiel werden die Merkmale
gain,hoursundspeedberechnet. - Neu erzeugte Variablen können sofort verwendet werden (hier:
hoursfürspeed.
(flights_sml <- flights |>
select(year:day,
ends_with("delay"),
distance,
air_time ) |>
mutate(gain = dep_delay - arr_delay,
hours = air_time / 60,
speed = distance / hours))# A tibble: 336,776 × 10
year month day dep_delay arr_delay distance air_time gain hours speed
<int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2013 1 1 2 11 1400 227 -9 3.78 370.
2 2013 1 1 4 20 1416 227 -16 3.78 374.
3 2013 1 1 2 33 1089 160 -31 2.67 408.
4 2013 1 1 -1 -18 1576 183 17 3.05 517.
5 2013 1 1 -6 -25 762 116 19 1.93 394.
6 2013 1 1 -4 12 719 150 -16 2.5 288.
7 2013 1 1 -5 19 1065 158 -24 2.63 404.
8 2013 1 1 -3 -14 229 53 11 0.883 259.
9 2013 1 1 -3 -8 944 140 5 2.33 405.
10 2013 1 1 -2 8 733 138 -10 2.3 319.
# ℹ 336,766 more rowsBemerkung zum obigen Beispiel:
Die Funktion select() im obigen Beispiel hat lediglich die Funktion die Datentabelle nicht zu breit werden zu lassen. Daher habe ich nicht notwendige Spalten herausgefiltert.
8.6.2 Die Funktion transmute
- Die Funktion
transmute()funktioniert prinzipiell genau wie die Funktionmutate(), allerdings werden nur die neu erzeugten Merkmale behalten. - Merkmale der ursprünglichen Datentabelle können einfach übernommen werden. Wird kein neuer Name angegeben, so bleibt der alte bestehen (hier:
distance).
flights |> transmute(distance,
gain = dep_delay - arr_delay,
hours = air_time / 60,
speed = distance / hours)# A tibble: 336,776 × 4
distance gain hours speed
<dbl> <dbl> <dbl> <dbl>
1 1400 -9 3.78 370.
2 1416 -16 3.78 374.
3 1089 -31 2.67 408.
4 1576 17 3.05 517.
5 762 19 1.93 394.
6 719 -16 2.5 288.
7 1065 -24 2.63 404.
8 229 11 0.883 259.
9 944 5 2.33 405.
10 733 -10 2.3 319.
# ℹ 336,766 more rows
8.6.3 Die Funktion rename()
- Mit der Funktion
rename()können eine oder mehrere, durch Komma getrennte Merkmale, umbenannt werden. Dabei steht der neue Name vor dem Gleichheitszeichen, der alte nach dem Gleichheitszeichen.
flights |> select(contains("time")) |>
rename(flight_time = air_time,
date_time = time_hour)# A tibble: 336,776 × 6
dep_time sched_dep_time arr_time sched_arr_time flight_time
<int> <int> <int> <int> <dbl>
1 517 515 830 819 227
2 533 529 850 830 227
3 542 540 923 850 160
4 544 545 1004 1022 183
5 554 600 812 837 116
6 554 558 740 728 150
7 555 600 913 854 158
8 557 600 709 723 53
9 557 600 838 846 140
10 558 600 753 745 138
# ℹ 336,766 more rows
# ℹ 1 more variable: date_time <dttm>
8.6.4 Einzelne Merkmale ändern mit mutate()
Merkmale können mit der Funktion mutate() auch geändert / bearbeitet werden.
## Ändern des Merkmals distance von km in m:
# Überschreiben des alten Merkmals durch Zuweisung = :
(flights_sml |> mutate(distance = distance * 1000) |>
slice_head(n = 3))# A tibble: 3 × 10
year month day dep_delay arr_delay distance air_time gain hours speed
<int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2013 1 1 2 11 1400000 227 -9 3.78 370.
2 2013 1 1 4 20 1416000 227 -16 3.78 374.
3 2013 1 1 2 33 1089000 160 -31 2.67 408.# Mit across() und einer Funktion (empfohlen!):
# Die Einträge von distance werden mit Hilfe der Funktion geändert
(flights_sml |> mutate(across(distance, function(x) {x*1000}))|>
slice_head(n = 3))# A tibble: 3 × 10
year month day dep_delay arr_delay distance air_time gain hours speed
<int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2013 1 1 2 11 1400000 227 -9 3.78 370.
2 2013 1 1 4 20 1416000 227 -16 3.78 374.
3 2013 1 1 2 33 1089000 160 -31 2.67 408.Bemerkungen:
Die Funktion innerhalb der Funktion
across()muss genau ein Argument haben. Das Argument darf einen beliebigen Namen haben.Hat eine Funktion mehrere benötigte oder genutzte Argumente, so erstellt man einen neue Funktion, die nur noch von einem Argument abhängig ist.
Statt
function(x)kann seit der R-Version 4.1 auch die abkürzende Schreibweise\(x)benutzt werden, wobei ein beliebiges Argument benutzt werden kann, das heißt das Argument muss nichtxheißen.-
Ist die Funktion, die innerhalb der Funktion
across()auf die Merkmale angewendet werden soll, komplizierter (also länger) oder wird sie mehrfach benötigt, so ist es ratsam diese zuvor außerhalb des Pipe-Ausdrucks zu definieren. Achten Sie dabei auf die Syntax:- der Code der Funktion muss in geschweifte Klammern gesetzt werden,
- macht die Funktion mehr als eine einfache Rechnung, so muss einen Rückgabewert mit der Funktion mit der Funktion
return()angegeben werden.
Beispiel
Es soll eine Funktion geschrieben werden, die das gleiche macht wie die Funktion sum(), aber der Standard soll sein NAs zu ignorieren.
8.6.5 Mehrere Merkmale ändern mit mutate()
- In vielen Fällen ist es erforderlich, dass man mehrere Merkmale auf die gleiche Art und Weise ändern möchte.
- Dies gelingt mit Hilfe der Funktion
across()sowie den Auswahlfunktionen aus demtidyselect, die bereits im Abschnitt über die Funktionselect()beschrieben wurden.
Beispiele:
Wir betrachten als Beispiel die folgende Datentabelle
umfrage# A tibble: 3 × 6
Name X1 X2 Y1 X3 Y2
<chr> <dbl> <dbl> <chr> <dbl> <chr>
1 Anton 1 1 Ja 2 ja
2 Bert 3 2 Nein 5 Ja
3 Celina 5 4 ja 3 Nein Folgende Änderungen möchten wir nun mit Hilfe der Funktion mutate() vornehmen:
- Bei den numerischen Merkmalen
X1,X2undX3wollen wir von jedem Wert 1 abziehen. * Bei den Merkmalen deren Ausprägung ja bzw. nein sind wollen die Groß- und Kleinschreibung vereinheitlichen.
# Von den metrischen Merkmalen 1 abziehen:
umfrage |> mutate(across(starts_with("X"),
\(n) {n-1}))# A tibble: 3 × 6
Name X1 X2 Y1 X3 Y2
<chr> <dbl> <dbl> <chr> <dbl> <chr>
1 Anton 0 0 Ja 1 ja
2 Bert 2 1 Nein 4 Ja
3 Celina 4 3 ja 2 Nein Erklärung: Innerhalb der Funktion across() stehen zwei Argumente:
das erste Argument gibt an welche Spalten geändert werden sollen, dabei sind die tidyselect-Funktionen, wie zum Beispiel
starts_with(),ends_with(),contains()etc. erlaubt. Da genau die zu änderndern Merkmale mitXbeginnen bietet sich die obige Möglichkeit der Änderung an.Das zweite Argument ist eine Funktion. Diese kann entweder bereits bestehen oder selbst geschrieben werden, wie im obigen Beispiel. Dabei ist
\(n) {n-1}das Gleiche wiefunction(n) {n-1}. Diese Funktion wird auf alle Merkmale (Spalten), die ausgewählt wurden, angewendet.
# "ja" zu "Ja" konvertieren:
hilfe <- \(x) {ifelse(x == "ja", "Ja", x)}
umfrage |> mutate(across(where(is.character), hilfe))# A tibble: 3 × 6
Name X1 X2 Y1 X3 Y2
<chr> <dbl> <dbl> <chr> <dbl> <chr>
1 Anton 1 1 Ja 2 Ja
2 Bert 3 2 Nein 5 Ja
3 Celina 5 4 Ja 3 Nein Zuerst haben wir uns die Funktion hilfe() definiert. In der Funtion across() steht nun, dass die Funktion hilfe() alle Merkmale (Spalten) angewendet wird, die vom Typ Character, also Zeichenketten, sind.
Im obigen Fall wäre das auch das Merkmal Name, was man an der Stelle ggf. nicht haben möchte (aber egal ist, da ja nicht als Ausprägung im Merkmal Name vorkommt). Andere Möglichkeiten um in der obigen Tabelle die Merkmale Y1 und Y2 auf die gewünschte Art zu ändern wären:
umfrage |> mutate(across(starts_with("Y"), hilfe))
umfrage |> mutate(across(contains("Y"), hilfe))
umfrage |> mutate(across(num_range("Y",1:2), hilfe))Wichtige Bemerkung:
Wenn Sie im Internetz nach Hilfe suchen, werden Sie verschiedene Syntaxen für die Verwendung der Funktion across() finden. Die folgenden Schreibweisen liefern das gleiche Ergebnis:
hilfe <- \(x) {ifelse(x == "ja", "Ja", x)}
umfrage |> mutate(across(where(is.character),
hilfe))
# ist das gleiche wie
umfrage |> mutate(across(where(is.character),
function(x) {ifelse(x == "ja", "Ja", x)}))
# oder kurz
umfrage |> mutate(across(where(is.character),
\(x) {ifelse(x == "ja", "Ja", x)}))
# oder (und das ist konzeptionell ein wenig anders, und veraltet!)
umfrage |> mutate(across(where(is.character),
~ifelse(.x == "ja", "Ja", .x)))Wesentliche Unterschiede des letzten Aufrufs:
- Vor der anzuwendende Funktion (hier:
ifelse()) in der Funktionacross()steht eine Tilde. - Der Funktion können alle Argumente mitgegeben werden.
- Das Argument, das sich auf die Spalten, die geändert werden sollen bezieht, muss
.xheißen!
Bemerkungen:
Der Ausdruck innerhalb der Funktion
where(), ist selbst eine Funktion (hier:is.character(), hat aber keine Klammern! (siehe Hilfewhere()imtidyselect).Die Funktion
is.character()istTRUE, falls das Argument (Vektor) eine Zeichenkette ist, sonstFALSE. Zum jedem Daten- / Objekttyp gibt es analoge Funktionen wie zu, Beispielis.numeric()(integer und double),is.double(),is.integer(),is.logical(), etc.
8.6.6 Kombinieren von Merkmalen mehrerer Spalten
Es kommt vor, dass wir neue Merkmale erstellen wollen, die sich aus anderen Merkmalen zusammensetzen. In einfachen Fällen, wie in Kapitel 8.6.1 kann man dies durch arithmetische Operationenin denen die benötigten Merkmale direkt genannt werden erledigen. Möchten wir Funktionen wie sum(), mean() oder median() etc. nutzen, so funktioniert dies nicht ohne weiteres, wie das folgende Beispiel zeigt.
daten # A tibble: 11 × 5
x1 x2 y1 x3 y2
<dbl> <dbl> <dbl> <dbl> <dbl>
1 1 1 1 1 1
2 2 0 3 3 2
3 8 0 3 3 5
4 2 2 4 2 0
5 1 6 4 4 4
6 1 1 4 3 2
7 2 5 4 3 0
8 6 4 4 2 2
9 4 2 4 4 2
10 3 1 4 3 2
11 4 3 3 4 1# A tibble: 11 × 7
x1 x2 y1 x3 y2 z1 z2
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1 1 1 1 1 3 91
2 2 0 3 3 2 5 91
3 8 0 3 3 5 11 91
4 2 2 4 2 0 6 91
5 1 6 4 4 4 11 91
6 1 1 4 3 2 5 91
7 2 5 4 3 0 10 91
8 6 4 4 2 2 12 91
9 4 2 4 4 2 10 91
10 3 1 4 3 2 7 91
11 4 3 3 4 1 11 91Was man am obigen Beispiel sieht ist, dass beim Merkmal z1 genau das passiert, was man erwartet, nämlich eine zeilenweise Addition der Merkmale x1, x2, x3. Mit der funktion sum() funktioniert dies nicht in der gewünschten Form. Hier werden alle Zahlen aus x1, x2 und x3 addiert.
Es gibt nun aber die Möglichkeit auch zeilenweise Operationen auszuführen, die zum einen Funktionen zulassen und zum anderen auch eine Auswahl der Merkmale mit den tidyselect-Funktionen. Dazu benötigen wir das Funktionenpaar rowwise() und c_across().
Somit könnte das obige Beispiel in der folgenden Form geschrieben werden.
daten |> rowwise() |>
mutate(z2 = sum(c_across(starts_with("x")))
)# A tibble: 11 × 6
# Rowwise:
x1 x2 y1 x3 y2 z2
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1 1 1 1 1 3
2 2 0 3 3 2 5
3 8 0 3 3 5 11
4 2 2 4 2 0 6
5 1 6 4 4 4 11
6 1 1 4 3 2 5
7 2 5 4 3 0 10
8 6 4 4 2 2 12
9 4 2 4 4 2 10
10 3 1 4 3 2 7
11 4 3 3 4 1 11Die beiden Funktionen rowwise() und c_across() werden immer gemeinsam verwendet, wenn man zeilenweise operieren möchte. Die Funktion c_across() ist der Funktion c() sehr ähnlich, mit dem Unterschied, dass c_across() auch tidyselect-Auswahlen akzeptiert.
8.7 Kenngrößen von Gruppen berechnen
summarise() und group_by()
- Mit der Funktion
summarise()(oder auchsummarize()) ist es möglich, die Datentabelle auf eine einzelne Zeile zu reduzieren.
flights |> summarise(delay = mean(dep_delay,
na.rm = TRUE))# A tibble: 1 × 1
delay
<dbl>
1 12.6Im obigen Beispiel wird das arithmetische Mittel
mean()der Verspätungen beim Abflug über alle Flüge berechnet, wobei fehlende Einträge ignoriert wurden (na.rm = TRUE).Mit der Funktion
group_by()können Gruppen gebildet werden (genau genommen wird die Datentabelle zu einer gruppierten Datentabelle). Die Funktionsummarise()operiert nun auf den Gruppen.
Beispiel 1
flights |> group_by(month) |>
summarise(delay = mean(dep_delay, na.rm = TRUE))# A tibble: 12 × 2
month delay
<int> <dbl>
1 1 10.0
2 2 10.8
3 3 13.2
4 4 13.9
5 5 13.0
6 6 20.8
7 7 21.7
8 8 12.6
9 9 6.72
10 10 6.24
11 11 5.44
12 12 16.6 In diesem Beispiel wird nach den Ausprägungen des Merkmals month gruppiert. Danach wird bezüglich dieser Gruppen jeweils das arithmetische Mittel gebildet.
Es ist zu bemerken, dass die resultierende Datentabelle immer alle Merkmale hat, die
- in der Funktion
group_by()stehen, - in der Funktion
summarise()gebildet werden.
Beispiel 2
Es ist möglich nach mehreren Merkmalen gleichzeitig zu gruppieren. Im folgenden Beispiel werden 365 Gruppen begildet.
# Gruppieren nach mehreren Merkmalen:
flights |> group_by(month, day) |>
summarise(delay = mean(dep_delay, na.rm = TRUE))`summarise()` has grouped output by 'month'. You can override using the
`.groups` argument.# A tibble: 365 × 3
# Groups: month [12]
month day delay
<int> <int> <dbl>
1 1 1 11.5
2 1 2 13.9
3 1 3 11.0
4 1 4 8.95
5 1 5 5.73
6 1 6 7.15
7 1 7 5.42
8 1 8 2.55
9 1 9 2.28
10 1 10 2.84
# ℹ 355 more rowsBemerkung
Die resultierende Datentabelle ist immer noch bezüglich des Montas gruppiert, wohingegen die Gruppierung aufgrund der Funktion summarise() nicht mehr vorhanden ist, da auf der Ebene die Mittelwertbildung stattgefunden hat: in der resultierenden Datentabelle gibt es jede Ausprägung des Merkmals day genau einmal.
8.7.1 Darstellen gruppierter Daten:
Die folgende Grafik ist ein typisches Beispiel dafür, wie aus einer Datentabelle eine Grafik entsteht, wobei die dargestellten Größen aus der Datentabelle berechnet werden.
flights |> group_by(dest) |>
summarise(count = n(),
dist = mean(distance, na.rm = TRUE),
delay = mean (arr_delay, na.rm = TRUE)) |>
filter (count > 20, dest != "HNL") |>
ggplot(aes(x = dist, y = delay)) +
geom_point(aes(size = count), alpha = 1/3) +
geom_smooth(se = FALSE) +
labs(x = "Distanz", y = "Mittlere Verspätung")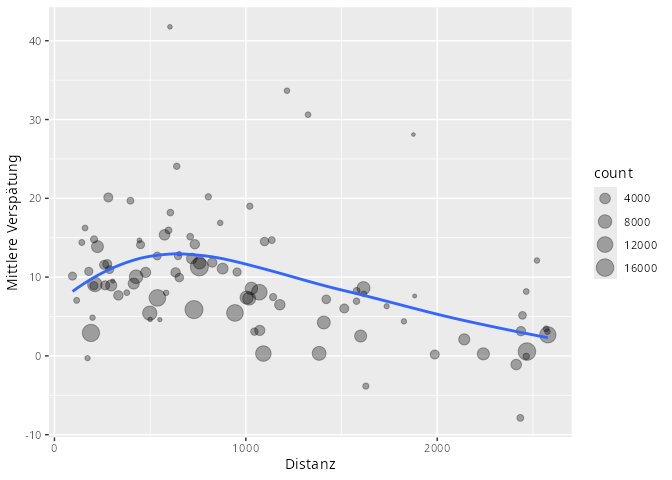
Der Pipe-Operator macht diese Operationen von links nach rechts lesbar:
Zuerst werden die Flüge nach Zielflughafen gruppiert.
-
Dann werden die interessanten statistischen Merkmale bezüglich der zuvor gebildeten Gruppen aggregiert.
- Anzahl der Flüge,
- durchschnittliche Flugdistanz,
- durchschnittliche Verspätung bei der Ankunft.
Danach werden einige Flüge ausgeschlossen (d.h. herausgefiltert): nämlich zum einen die Flughäfen, die in dem Jahr 20 oder weniger Anflüge hatten und zum anderen die Flüge nach Honululu, da die entfernung da hin sehr viel weiter ist als alle anderen.
Zuletzt werden die aggregierten Kenngrößen in einer Grafik mit verschiedenen Schichten dargestellt.
Um das Erstellen von Abbildung 8.5 zu verdeutlichen, soll die generierte Datentabelle noch einmal isoliert betrachtet werden:
flights |>
group_by(dest) |>
summarise(count = n(),
dist = mean(distance, na.rm = TRUE),
delay = mean (arr_delay, na.rm = TRUE))# A tibble: 105 × 4
dest count dist delay
<chr> <int> <dbl> <dbl>
1 ABQ 254 1826 4.38
2 ACK 265 199 4.85
3 ALB 439 143 14.4
4 ANC 8 3370 -2.5
5 ATL 17215 757. 11.3
6 AUS 2439 1514. 6.02
7 AVL 275 584. 8.00
8 BDL 443 116 7.05
9 BGR 375 378 8.03
10 BHM 297 866. 16.9
# ℹ 95 more rows- Die mit der Funktion
summarise()erstellten Merkmale beziehen sich alle auf die gruppierten Daten. Daher ist das erste Merkmal der generierten Datentabelledest. - Das zweite Merkmal ist
count, erstellt mit der Funktionn(). Diese zählt, wie oft jede Ausprägung des Merkmalsdestin der ursprünglichen Datentabelleflightsvorkommt. - Die Merkmale
distunddelaysind die arithmetischen Mittel der Merkmaledistanceundarr_delayinnerhalb jeder Gruppe, also für jeden Zielflughafen. In beidem Fällen werden fehlende Werte ignoriert (na.rm = TRUE).
8.7.2 Gruppieren nach mehreren Merkmalen
daily <- flights |> group_by(year, month, day)- Jede Zusammenfassung mit
summarise()entfernt die oberste Ebene der Gruppierungen. - Damit können schrittweise Zusammenfassungen je Gruppierungsebenen erstellt werden.
(per_day <- daily |>
summarise(flights = n()))`summarise()` has grouped output by 'year', 'month'. You can override using the
`.groups` argument.# A tibble: 365 × 4
# Groups: year, month [12]
year month day flights
<int> <int> <int> <int>
1 2013 1 1 842
2 2013 1 2 943
3 2013 1 3 914
4 2013 1 4 915
5 2013 1 5 720
6 2013 1 6 832
7 2013 1 7 933
8 2013 1 8 899
9 2013 1 9 902
10 2013 1 10 932
# ℹ 355 more rows(per_month <- per_day |>
summarise(flights = sum(flights)))`summarise()` has grouped output by 'year'. You can override using the
`.groups` argument.# A tibble: 12 × 3
# Groups: year [1]
year month flights
<int> <int> <int>
1 2013 1 27004
2 2013 2 24951
3 2013 3 28834
4 2013 4 28330
5 2013 5 28796
6 2013 6 28243
7 2013 7 29425
8 2013 8 29327
9 2013 9 27574
10 2013 10 28889
11 2013 11 27268
12 2013 12 28135(per_year <- per_month |>
summarise(flights = sum(flights)))# A tibble: 1 × 2
year flights
<int> <int>
1 2013 336776
8.7.3 Gruppierungen aufheben: ungroup()
flights |>
group_by(year, month, day) |>
ungroup() |>
summarise(flights = n()) # A tibble: 1 × 1
flights
<int>
1 336776- Mit Hilfe der Funktion
ungroup()können Gruppierungen aufgehoben werden. - Wird
ungroup()ohne eine Argument verwendet, so werden alle Gruppierungen aufgehoben.
flights |>
group_by(year, month, day) |>
ungroup(year, day) |>
summarise(flights = n()) # A tibble: 12 × 2
month flights
<int> <int>
1 1 27004
2 2 24951
3 3 28834
4 4 28330
5 5 28796
6 6 28243
7 7 29425
8 8 29327
9 9 27574
10 10 28889
11 11 27268
12 12 28135
8.7.4 Filtern mit Gruppenwerten: group_by() und filter()
Im Beispiel rechts werden für jeden Tag die beiden Flüge mit der größten Ankunfts-Verspätung ermittelt.
flights |> group_by(year, month, day) |>
filter(rank(desc(arr_delay)) <= 2) |>
select(year, month, day, flight)# A tibble: 722 × 4
# Groups: year, month, day [365]
year month day flight
<int> <int> <int> <int>
1 2013 1 1 3944
2 2013 1 1 4321
3 2013 1 2 179
4 2013 1 2 488
5 2013 1 3 2027
6 2013 1 3 3459
7 2013 1 4 179
8 2013 1 4 3805
9 2013 1 5 3521
10 2013 1 5 1109
# ℹ 712 more rows- Im Beispiel rechts oben werden alle Flüge von Flughäfen mit mehr als 17000 Landungen im Jahr ermittelt.
flights |>
group_by(dest) |>
filter(n() > 17000) |>
select(year, month, day, flight, dest)# A tibble: 34,498 × 5
# Groups: dest [2]
year month day flight dest
<int> <int> <int> <int> <chr>
1 2013 1 1 461 ATL
2 2013 1 1 1696 ORD
3 2013 1 1 301 ORD
4 2013 1 1 4650 ATL
5 2013 1 1 1743 ATL
6 2013 1 1 3768 ORD
7 2013 1 1 575 ATL
8 2013 1 1 303 ORD
9 2013 1 1 305 ORD
10 2013 1 1 1547 ATL
# ℹ 34,488 more rows- Im Beispiel rechts unten werden alle Flüge ermittelt, die eine Ankunftsverspätung haben, die um mehr als das Dreifache der Standardabweichung vom Durchschnitt des Zielflughafens abweicht.
flights |>
group_by(dest) |>
filter( arr_delay > mean(arr_delay) + 3*sd(arr_delay) ) |>
select(dest, year, month, day, flight, tailnum, arr_delay)# A tibble: 5 × 7
# Groups: dest [1]
dest year month day flight tailnum arr_delay
<chr> <int> <int> <int> <int> <chr> <dbl>
1 ABQ 2013 10 15 65 N640JB 138
2 ABQ 2013 12 14 65 N659JB 149
3 ABQ 2013 12 17 65 N556JB 136
4 ABQ 2013 7 22 1505 N784JB 153
5 ABQ 2013 7 23 1505 N589JB 137
8.7.5 Fehlende Werte: NA
Fehlende Werte (
NA) in einer Datentabelle können dazu führen, dass statistische Aggregationen als ErgebnisNAliefern.Davon sind unter anderem die Funktionen
sum()(Summe),mean()(arithmetisches Mittel),median()(Median),var()(Varianz) undsd()(Standardabweichung) betroffen.Im Beispiel auf der rechten Seite wurde das Argument
na.rm = TRUEnicht gesetzt, was dazu führt, dass im Merkmaldelaysehr vieleNA-Werte auftreten.
flights |>
group_by(month, day) |>
summarise(delay = mean(dep_delay))`summarise()` has grouped output by 'month'. You can override using the
`.groups` argument.# A tibble: 365 × 3
# Groups: month [12]
month day delay
<int> <int> <dbl>
1 1 1 NA
2 1 2 NA
3 1 3 NA
4 1 4 NA
5 1 5 NA
6 1 6 NA
7 1 7 NA
8 1 8 NA
9 1 9 NA
10 1 10 NA
# ℹ 355 more rowsEs gibt verschiedene Möglichkeiten, fehlende Werte zu ignorieren: \
- Das Argument
na.rmder Funktionmean()auf den WahrheitswertTRUEgesetzt.
flights |>
group_by(month, day) |>
summarise(mean = mean(dep_delay, na.rm = TRUE))`summarise()` has grouped output by 'month'. You can override using the
`.groups` argument.# A tibble: 365 × 3
# Groups: month [12]
month day mean
<int> <int> <dbl>
1 1 1 11.5
2 1 2 13.9
3 1 3 11.0
4 1 4 8.95
5 1 5 5.73
6 1 6 7.15
7 1 7 5.42
8 1 8 2.55
9 1 9 2.28
10 1 10 2.84
# ℹ 355 more rows- Man kann auch mit der Funktion
filter()alle Zeilen herausgefiltert, bei denen der Ausdruck!is.na(dep_delay)den WahrheitswertFALSEhat. Dabei liefert Ausdruck!is.na(dep_delay)einen logischen Vektor, der genau dannFALSEist, falls eine Ausprägung vondep_delayden WertNAhat.
`summarise()` has grouped output by 'month'. You can override using the
`.groups` argument.# A tibble: 365 × 3
# Groups: month [12]
month day mean
<int> <int> <dbl>
1 1 1 11.5
2 1 2 13.9
3 1 3 11.0
4 1 4 8.95
5 1 5 5.73
6 1 6 7.15
7 1 7 5.42
8 1 8 2.55
9 1 9 2.28
10 1 10 2.84
# ℹ 355 more rowsDie letzte Methode ist alle Beobachtungen mit drop_na() auszusortieren, bei denen das Merkmal dep_delay den Wert NA hat. Die Funktion drop_na() kann auch mehrere Argumente haben, wobei dann alle Beobachtungen aussortiert werden, bei denen mindestens eines der angegebenen Merkmale fehlt, also den Wert NA hat.
flights |>
group_by(month, day) |>
drop_na(dep_delay) |>
summarise(mean = mean(dep_delay))`summarise()` has grouped output by 'month'. You can override using the
`.groups` argument.# A tibble: 365 × 3
# Groups: month [12]
month day mean
<int> <int> <dbl>
1 1 1 11.5
2 1 2 13.9
3 1 3 11.0
4 1 4 8.95
5 1 5 5.73
6 1 6 7.15
7 1 7 5.42
8 1 8 2.55
9 1 9 2.28
10 1 10 2.84
# ℹ 355 more rows
8.7.6 Anzahlen: n() und n_distinct()
Sobald man Daten aggregiert, ist es sinnvoll, die Anzahl der Beobachtungen je Gruppe mit der Funktion n()zu zählen. Will man nur die nicht-fehlenden Werte eines Merkmals zählen, verwendet man statt n() die Befehlssequenz sum(!is.na(<Merkmal>)).
Im Beispiel folgenden Beispiel wird nach der Flugzeugnummer gruppiert und danach die durchschnittliche Verspätung der Flugzeuge beim Abflug bestimmt.
flights |>
drop_na(dep_delay, arr_delay) |>
group_by(tailnum) |>
summarise(delay = mean(dep_delay)) |>
ggplot(aes(x = delay)) +
geom_freqpoly(binwidth = 5) 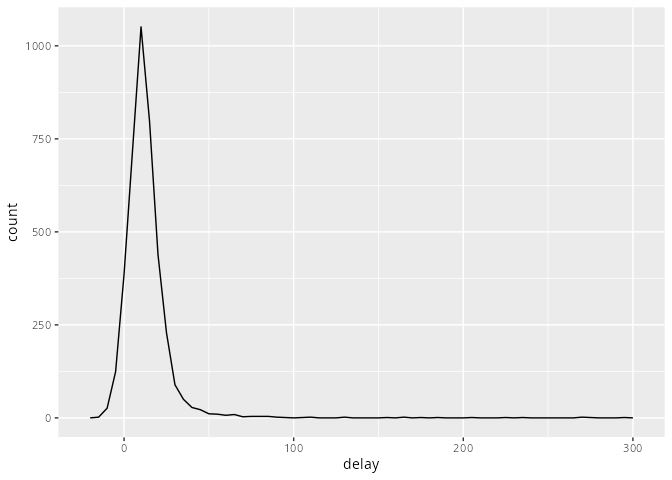
Man kann dem Plot entnehmen, dass es Flugzeuge gibt, die fünf Stunden (300 Minuten) Verspätung haben. Dies untersuchen wir im Folgenden detaillierter.
delays <- flights |>
drop_na(dep_delay, arr_delay) |>
group_by(tailnum) |>
summarise(delay = mean(dep_delay),
n = n())
delays |> ggplot(aes(x = n, y = delay)) +
geom_point(alpha = 0.1)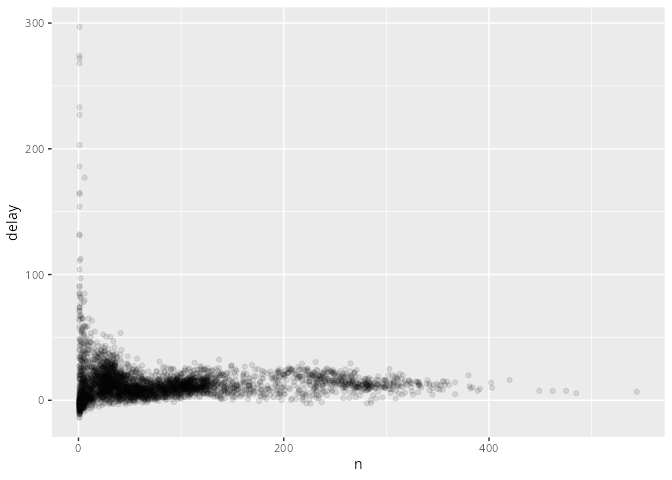
delays |> filter(n > 25) |>
ggplot(aes(x = n, y = delay)) +
geom_point(alpha = 0.1)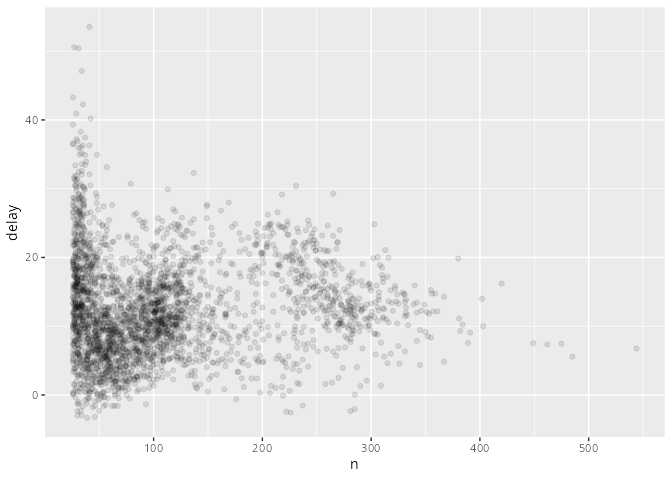
- Man sieht, dass die Verspätungen für selten startende Flugzeuge stärker streut.
- Bei der unteren Grafik werden nur Flugzeuge betrachtet, die öfter als 25 mal geflogen sind.
- Damit relativiert sich die Erkenntnis der letzten Seite: Die großen durchschnittlichen Verspätungen treten nur bei geringer Anzahl von Flügen auf.
Die Funktion n()zählt die Gesamtanzahl der jeweiligen Beobachtungen.Manchmal ist es aber interessant zu wissen wie viele verschiedene Beobachtung in einem Merkmal vorkommen. Dazu dient die Funktion n_distinct().
flights |> drop_na(dep_delay, arr_delay) |>
filter(dest == "ATL") |>
ggplot(aes(x = carrier)) +
geom_bar()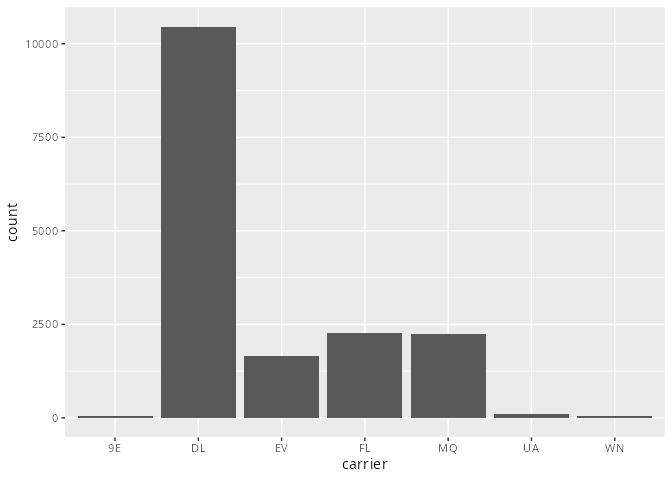
flights |> drop_na(dep_delay, arr_delay) |>
group_by(dest) |>
summarise(carriers = n_distinct(carrier),
n = n()) |>
arrange(desc(carriers))# A tibble: 104 × 3
dest carriers n
<chr> <int> <int>
1 ATL 7 16837
2 BOS 7 15022
3 CLT 7 13674
4 ORD 7 16566
5 TPA 7 7390
6 AUS 6 2411
7 DCA 6 9111
8 DTW 6 9031
9 IAD 6 5383
10 MSP 6 6929
# ℹ 94 more rowssummarise()
| Funktion | Art | Erklärung |
|---|---|---|
mean() |
Lagemaß | arithmetisches Mittel |
median() |
Lagemaß | Median |
sd() |
Streumaß | (Stichproben-)Standardabweichung |
var() |
Streumaß | (Stichproben-)Varianz |
IQR() |
Streumaß | Interquartilsabstand |
mad() |
Streumaß | mittlere absolute Abweichung vom Median |
min() |
Rangmaß | Minimum |
quantile() |
Rangmaß | Quantile |
max() |
Rangmaß | Maximum |
first() |
Positionsmaß | das erste Element: first(x) entspricht x[1]
|
nth() |
Positionsmaß | das (n)-te Element: nth(x, 5) entspricht x[5]
|
last() |
Positionsmaß | Das letzte Element: last(x) entspricht x[length(x)]
|
n() |
Anzahl | Gesamtanzahl der Beobachtungen |
n_distinct() |
Anzahl | Anzahl der verschiedenen Beobachtungen |
sum() |
Summe | Summe von Werten; nützlich ist die Summe über Wahrheitswerte, z.B. sum(is.na()) oder sum(<Bedingung>)
|
Beispiele:
# first_dep: erster Flug am Tag
# last_dep: letzter Flug am Tag
flights |>
drop_na(dep_delay, arr_delay) |>
group_by(year, month, day) |>
summarise(first_dep = first(dep_time),
last_dep = last(dep_time))`summarise()` has grouped output by 'year', 'month'. You can override using the
`.groups` argument.# A tibble: 365 × 5
# Groups: year, month [12]
year month day first_dep last_dep
<int> <int> <int> <int> <int>
1 2013 1 1 517 2356
2 2013 1 2 42 2354
3 2013 1 3 32 2349
4 2013 1 4 25 2358
5 2013 1 5 14 2357
6 2013 1 6 16 2355
7 2013 1 7 49 2359
8 2013 1 8 454 2351
9 2013 1 9 2 2252
10 2013 1 10 3 2320
# ℹ 355 more rows# Anzahl der verschiedenen Carrier
flights |> drop_na(dep_delay, arr_delay) |>
group_by(dest) |>
summarise(carriers = n_distinct(carrier)) |>
arrange(desc(carriers))# A tibble: 104 × 2
dest carriers
<chr> <int>
1 ATL 7
2 BOS 7
3 CLT 7
4 ORD 7
5 TPA 7
6 AUS 6
7 DCA 6
8 DTW 6
9 IAD 6
10 MSP 6
# ℹ 94 more rows# Ausgehende Flüge vor 5:00 Uhr:
flights |> drop_na(dep_delay, arr_delay) |>
group_by(year, month, day) |>
summarise(n_early = sum(dep_time < 500))`summarise()` has grouped output by 'year', 'month'. You can override using the
`.groups` argument.# A tibble: 365 × 4
# Groups: year, month [12]
year month day n_early
<int> <int> <int> <int>
1 2013 1 1 0
2 2013 1 2 3
3 2013 1 3 4
4 2013 1 4 3
5 2013 1 5 3
6 2013 1 6 2
7 2013 1 7 2
8 2013 1 8 1
9 2013 1 9 3
10 2013 1 10 3
# ℹ 355 more rows
8.8 Die slice_* Funktionen
Es gibt eine sehr praktische Funktionenfamilie, um (ggf.innerhalb von gruppierten Daten) spezielle Zeilen auszuwählen:
-
slice_head(n = 1)zeigt die erste Zeile jeder Gruppe. -
slice_tail(n = 1)zeigt die letzte Zeile jeder Gruppe. -
slice_min(x, n = 1)zeigt die Zeile mit dem kleinsten Wert vonx. -
slice_max(x, n = 1)zeigt die Zeile mit dem größten Wert vonx. -
slice_sample(n = 1)wählt eine zufällige Zeile aus.
Bemerkungen:
- Das Argument
n =kann natürlich variieren, außerdem kann ein mit dem Argumentprop =ein Anteil angegeben werden: zum Beispiel wähltprop = 0.1die jeweiligen 10% der Gruppen aus. - Die
slice_sample()Funktion ist praktisch, um aus einem großen Datensatz kleinere Datensätze zu ziehen (z.B. beim Bootstrapping) oder fürggpairs(). - Bei Gleichständen werden alle Werte in der resultierenden Datentabelle gezeigt. Dies kann mit
with_ties = FALSEgeändert werden (siehe Hilfe).
Beispiele:
Im folgenden Beispiel werden die 13 größten Verspätungen arr_delay angezeigt. Die Funktion select() dient nur dazu die Ausgabe ein wenig übersichtlicher zu gestalten.
flights |> select(month, day, carrier, flight, arr_delay) |>
slice_max(arr_delay, n = 13)# A tibble: 13 × 5
month day carrier flight arr_delay
<int> <int> <chr> <int> <dbl>
1 1 9 HA 51 1272
2 6 15 MQ 3535 1127
3 1 10 MQ 3695 1109
4 9 20 AA 177 1007
5 7 22 MQ 3075 989
6 4 10 DL 2391 931
7 3 17 DL 2119 915
8 7 22 DL 2047 895
9 12 5 AA 172 878
10 5 3 MQ 3744 875
11 12 14 DL 2391 856
12 5 19 AA 257 852
13 1 1 MQ 3944 851Die slice-* Funktionen operieren auch auf gruppierten Daten. Im Folgenden wird bezüglich des Merkmals month gruppiert und für jeden Monat die 3 größten Verspätungen angezeigt.
flights |> select(month, day, carrier, flight, arr_delay) |>
group_by(month) |>
slice_max(arr_delay, n = 3)# A tibble: 37 × 5
# Groups: month [12]
month day carrier flight arr_delay
<int> <int> <chr> <int> <dbl>
1 1 9 HA 51 1272
2 1 10 MQ 3695 1109
3 1 1 MQ 3944 851
4 2 10 F9 835 834
5 2 24 DL 575 773
6 2 19 DL 2319 767
7 3 17 DL 2119 915
8 3 18 DL 2363 784
9 3 18 EV 4326 506
10 4 10 DL 2391 931
# ℹ 27 more rows