── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.6
✔ forcats 1.0.1 ✔ stringr 1.6.0
✔ ggplot2 4.0.1 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.2
✔ purrr 1.2.0
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors2 Tidyverse
2.1 Überblick
Tidyverse ist eine Paketsammlung mit der man Daten einzulesen, verarbeiten, modellieren und visualisieren kann. Bevor wir uns im nächsten Kapitel auf das Visualisieren mit ggplot2 stürzen, soll es hier eine kurze Übersicht geben, was das Tidyverse eigentlich ist.
Das Tidyverse ist nicht ein einzelnes Paket, sondern eine Sammlung von Paketen. Lädt man das Tidyverse, so sieht man die wichtigsten Paketen und deren aktuell installierte Version. Für eine komplette Liste der Tidyverse Pakete gibt es die Funktion
[1] "broom" "conflicted" "cli" "dbplyr"
[5] "dplyr" "dtplyr" "forcats" "ggplot2"
[9] "googledrive" "googlesheets4" "haven" "hms"
[13] "httr" "jsonlite" "lubridate" "magrittr"
[17] "modelr" "pillar" "purrr" "ragg"
[21] "readr" "readxl" "reprex" "rlang"
[25] "rstudioapi" "rvest" "stringr" "tibble"
[29] "tidyr" "xml2" "tidyverse" Tidyverse arbeitet mit rechteckigen Datentabellen, den Tibbles tibble (oder Data Frames).
Erhobene Daten müssen immer zuerst importiert und in einen bereinigten (tidy) Tibble gebracht werden, bevor man die Daten visualisieren, analysieren und modellieren kann. Für jede dieser Aufgaben gibt es ein Paket, das Teil des Tidyverses ist, und um einen besseren Überblick zu erhalten werden wir im nächsten Kapitel einen Überblick über diese Pakete geben.
2.2 Die Kern-Pakete
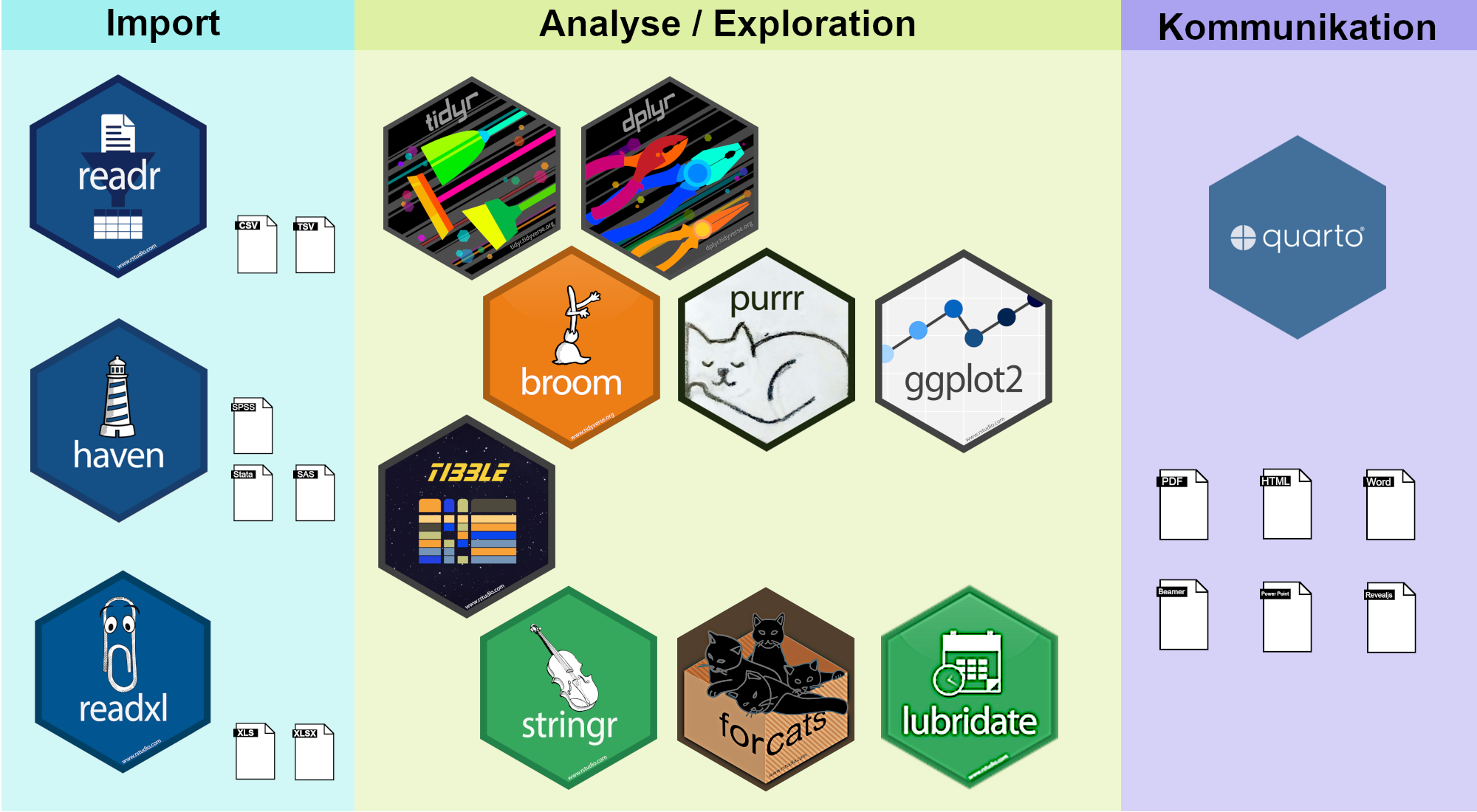
2.2.1 Import
readr: Mit dem Paket
readrkönnen Dateien imcsvodertsvFormat eingelesen werden. Dies sind reine Textdateien bei dem die Merkmale (Spalten) durch Komma, Semikolon, Tab oder einem beliebigen anderen (Spalten-)Trenner getrennt sind.readxl: Mit
readxlkönnen Excel-Dateien eigelesen werden. Diese enden auf.xlsoder.xlsx.haven: Das Paket
havendient dazu Dateien einzulesen, die mit Hilfe der Statsitikprogramme SPSS, SAS oder Stata erzeugt wurden.
2.2.2 Analyse / Exploration
Der Namensgeber des Tidyverse tidyr dient dazu Datentabellen zu bereinigen. Mit dem Paket dplyr können Daten (im positivsten Sinne) manipuliert werden: Merkmale können gefilter, sortiert, entfernt oder umbenannt werden, man kann Ausprägungen der Merkmale ändern oder neue Merkmale erstellen. Ebenso können auch Kenngrößen aus vorhandenen Merkmalen berechnet werden. Eine Erweiterung liefert das Paket purrr mit dem Funktionen auf den Daten angewendet werden können, so dass die Resultate nicht notwendigerweise Tibbles sein müssen.
ggplot2 ist das Paket mit dem Grafiken aus Datentabellen erstellt werden können.
Die Pakete stringr, forcats und lubridate bzw. hms helfen im Umgang mit Zeichenketten, Faktoren (kategoriale Merkmale) und Datums- bzw. Zeitangaben.
Das Paket broom beeinhaltet eine Sammlung von über 100 (statistischen) Modellen zur Analyse der Daten.
2.2.3 Kommunikation
Quarto ist eine Software um pdf- oder MS Word-Dokumente, html-Seiten, Beamer-, Revealjs- oder Power Point-Präsentationen zu erstellen. Quarto ist nicht im Paket tidyverse enthalten, wird aber von RStudio unterstützt und muss auf dem Rechner installiert werden.
In dem Moment in dem man eine Präsentation oder ein Dokument erstellen möchte, das R-Code und / oder aus Daten erzeugte Grafiken oder Tabellen enthält, lohnt es sich Quarto zu verwenden. Ein großer Vorteil ist, dass R-Code (oder auch Python-Code) einfach integriert werden kann, so dass Grafiken oder Tabellen dynamisch in dem jeweiligen Dokument erzeugt werden können. Das vereinfacht das Erstellen von Dokumenten ungemein, da nicht mehrere Programme nebeneinander genutzt werden müssen.