15 Faktoren
Faktoren sind die Datenstruktur in R für kategoriale, das heißt nominale (<fct>) und ordinale (<ord>) Merkmale, also Merkmale, die endlich viele bekannte und feste Ausprägungen haben. Die offensichtlichen Vorteile sind
- Da die Ausprägungen fest stehen, fallen Tippfehler in den Daten schnell auf.
- Die Daten können nicht nur alphabetisch, sondern in einer beliebigen, sinnvollen Reihenfolge sortiert werden (z.B. Noten, Monatsnamen, etc.)
Zum Bearbeiten von Faktoren nutzt man das Paket forcats, welches fester Bestandteil des tidyverse ist. Es muss daher nicht zusätzlich geladen werden.
Bemerkungen:
Der Artikel Wrangling categorical data in R liefert einen ersten Einblick, sowie eine kurze geschichtliche Entwicklung der Faktoren in R.
Der Name
forcatsist nicht nur ein Anagramm von Factors, sondern auch eine Kurzform von for categorical variables.

15.1 Erstellen von Faktoren
Im folgenden Beispiel haben wir zwei Objekte x1 und x2. Das Merkmale sind die Monate (abgekürzt auf drei Buchstaben), wobei der Vektor x2 einen Tippfehler enthält.
Sortiert man dieses Merkmal, so erhält man eine (wenig sinnvolle) alphabetische Ordnung.
sort(x1)[1] "Apr" "Aug" "Dez" "Jul"Was man an der Stelle haben möchte ist eine Ordnung wie die Monate im Jahr vorkommen. Dies erreicht man, wenn man aus den Vektoren jeweils einen Faktor macht. Um einen Faktor zu erstellen, benötigt man die Levels, das heißt die möglichen Ausprägungen, die ein Faktor annehmen kann, wobei die Reihenfolge wichtig ist.
# Levels / mögliche Ausprägungen:
monate_levels <- c("Jan", "Feb", "Mär", "Apr", "Mai", "Jun",
"Jul", "Aug", "Sep", "Okt", "Nov", "Dez")[1] Apr Jul Aug Dez
Levels: Jan Feb Mär Apr Mai Jun Jul Aug Sep Okt Nov DezAm obigen Beispiel können wir sehen, dass nicht nur die im Vektor vorkommenden Ausprägungen des Vektors y1 angezeigt werden, sondern auch alle möglichen Ausprägungen, die Levels, die ein Vektor annehmen kann. Bei Tippfehlern (oder allgemein nicht vorkommenden Ausprägungen) werden diese zu NAs umgewandelt.
# Tippfehler werden zu NA:
y2 <- factor(x2, levels = monate_levels)
y2[1] Dez Apr <NA> Aug
Levels: Jan Feb Mär Apr Mai Jun Jul Aug Sep Okt Nov Dez# mit Warnung (aus dem readr-Paket!):
y2 <- parse_factor(x2, levels = monate_levels)Warning: 1 parsing failure.
row col expected actual
3 -- value in level set JumBemerkungen
Geben wir das Argument
levels=nicht an, so wird die alphabetische Reihenfolge genommen.Manchmal möchte man, dass die Reihenfolge der Ausprägungen in der diese im Vektor oder später dann in der Datentabelle genommen wird. Dies kann man mit
unique()oderfct_inorder()erreichen. Letzteres wird später nocheinmal erklärt.
[1] "B" "A" "D" "E" "N"[1] B A D A A B E E N
Levels: B A D E N- Eine Möglichkeit auf die Menge aller zulässigen Levels zuzugreifen ist die Funktion
levels()die einen Zeichenketten-Vektor liefert.
levels(y3)[1] "B" "A" "D" "E" "N"
15.1.1 Der Datensatz gss_cat
gss_cat# A tibble: 21,483 × 9
year marital age race rincome partyid relig denom tvhours
<int> <fct> <int> <fct> <fct> <fct> <fct> <fct> <int>
1 2000 Never married 26 White $8000 to 9999 Ind,near … Prot… Sout… 12
2 2000 Divorced 48 White $8000 to 9999 Not str r… Prot… Bapt… NA
3 2000 Widowed 67 White Not applicable Independe… Prot… No d… 2
4 2000 Never married 39 White Not applicable Ind,near … Orth… Not … 4
5 2000 Divorced 25 White Not applicable Not str d… None Not … 1
6 2000 Married 25 White $20000 - 24999 Strong de… Prot… Sout… NA
7 2000 Never married 36 White $25000 or more Not str r… Chri… Not … 3
8 2000 Divorced 44 White $7000 to 7999 Ind,near … Prot… Luth… NA
9 2000 Married 44 White $25000 or more Not str d… Prot… Other 0
10 2000 Married 47 White $25000 or more Strong re… Prot… Sout… 3
# ℹ 21,473 more rowsgsssteht für General Social Survey, eine US-Langzeitstudie der unabhängigen Organisation NORC an der University of Chicago.Weitere Informationen unter
?gss_cat.Mit der Funktion
count()kann man sich die Levels des Faktors anschauen:
gss_cat |> count(race)# A tibble: 3 × 2
race n
<fct> <int>
1 Other 1959
2 Black 3129
3 White 16395- Alternativ mit einem Säulen- oder Balkendiagramm. Der Standard ist, dass Levels, die keine Werte haben nicht dargestellt werden. Es ist allerdings möglich sich diese trotzdem anzeigen zu lassen mit der Funktion
scale_x_discrete(drop = FALSE).
gss_cat |>
ggplot(aes(race)) +
geom_bar()gss_cat |>
ggplot(aes(race)) +
geom_bar() +
scale_x_discrete(drop = FALSE)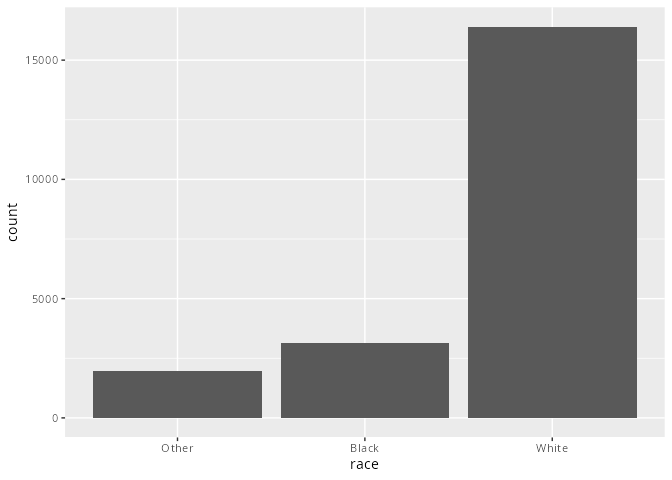
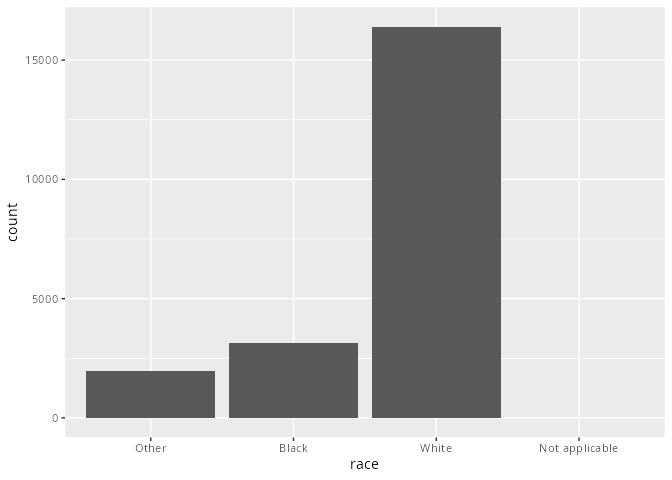
scale_x_discrete() werden alle Levels angezeigt, auch wenn diese keine Ausprägungen haben.
15.2 Ordnung der Levels
Bei der Visualisierung ist es oft sinnvoll die Reihenfolge der Levels zu ändern, um die Daten besser deuten zu können. Die Graphik oben rechts ist mühsam.
Mit der Funktion
fct_reorder()können die Faktoren geordnet werden. Im Beispiel wird das Merkmalf=relignach dem arithmetischen Mittel vonx=tvhourssortiert. Kommen Ausprägungen mehrfach vor, kann eine Funktion mit dem Argumentfun=angegeben werden (z.B:meanodersum, etc.) wie sortiert werden soll. Der Standard ist der Median.
relig_tv <- gss_cat |>
group_by(relig) |>
summarise(tvhours = mean(tvhours, na.rm = TRUE)
)relig_tv |>
ggplot(aes(tvhours, relig)) +
geom_point()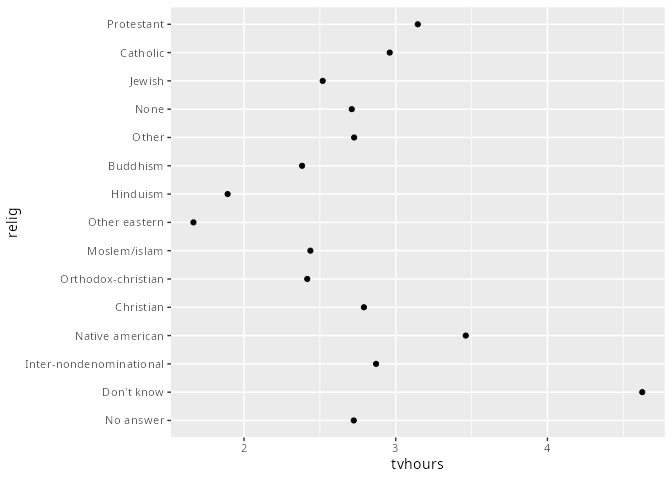
relig_tv |>
ggplot(aes(tvhours, fct_reorder(relig, tvhours))) +
geom_point()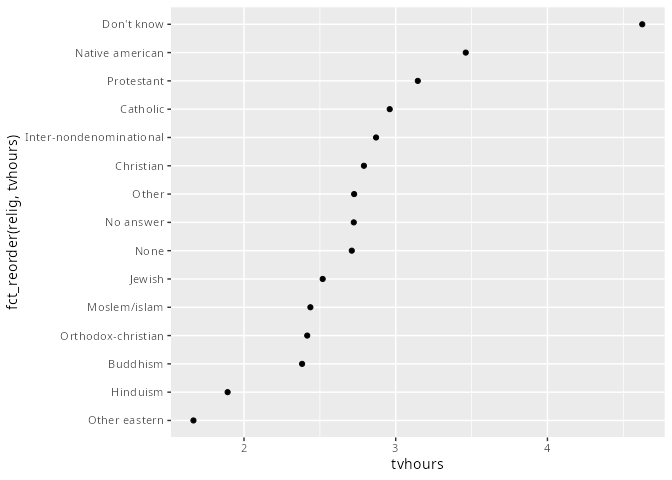
fct_reorder().
- Wenn die Transformationen komplizierter werden, ist es ratsam, diese aus der Funktion
aes()herauszunehmen, und den Faktor in der Datentabelle zu transformieren.
Dies liefert die gleiche Grafik wie Abbildung 15.5, allerdings ist die Syntax übersichtlicher.
Es ist nicht immer ratsam Faktoren umzuordnen, da sie oft bereits eine Ordnung haben. Allerdings kommt es vor, dass man einzelne Ausprägungen an den Anfang der Ordnung setzen möchte.
Dies geschieht mit der Funktion
fct_relevel(). Das folgende Beispiel zeigt, wie die Funktion funktioniert: Der erste Eintrag ist der Faktor, der neu geordnet werden soll, dahinter steht eine beliebige Anzahl von Ausprägungen, die nach vorne geschrieben werden sollen.
rincome_age <- gss_cat |>
group_by(rincome) |>
summarise(age = mean(age, na.rm = TRUE))rincome_age |>
ggplot(aes(age, fct_relevel(rincome, "Not applicable"))) +
geom_point()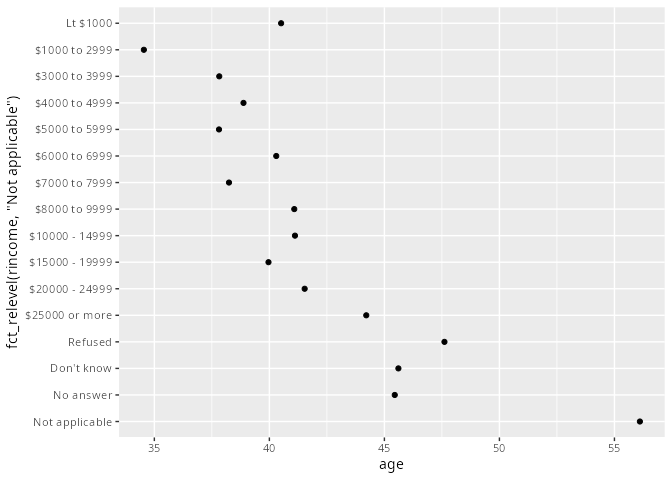
fct_relevel() ist der Faktor, der neu geordnet werden soll, dahinter steht eine beliebige Anzahl von Ausprägungen, die nach vorne geschrieben werden sollen.
Eine weitere Anwendung wäre die Färbung der Linien eines Plots zu ändern.
Die Funktion
fct_reorder2()ordnet den Faktor nach den y-Werten, der mit den höchsten x-Werten assoziiert wird. Dies macht die Graphik einfacher zu lesen, da Graphik und Legende besser zusammenpassen.
by_age |>
ggplot(aes(age, prop, colour = marital)) +
geom_line(na.rm = TRUE)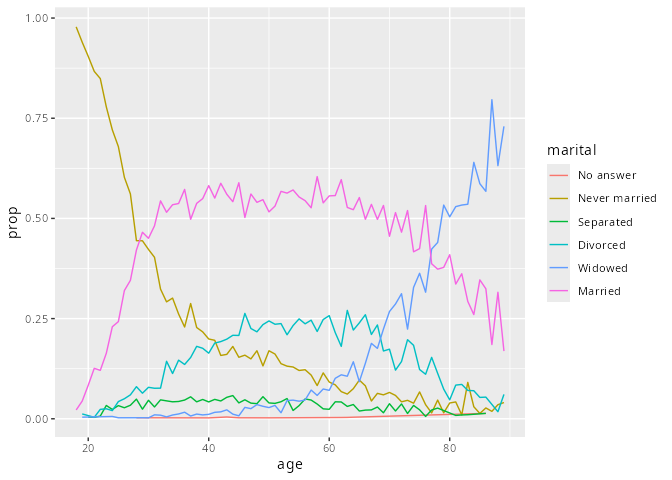
by_age |>
ggplot(aes(age, prop, colour = fct_reorder2(marital, age, prop))) +
geom_line() +
labs(colour = "marital")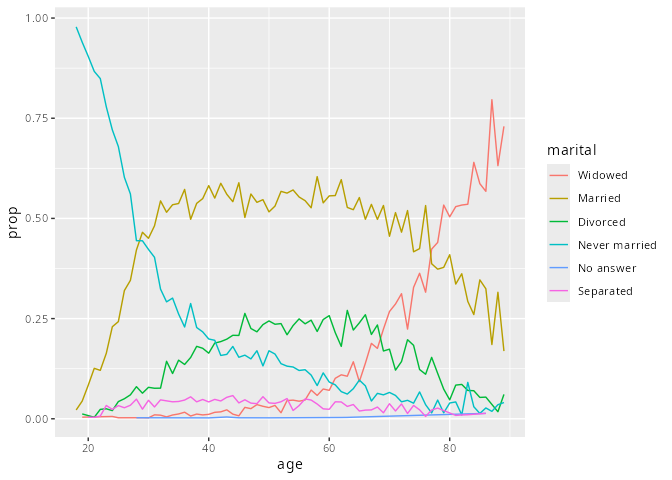
fct_reorder2() kann die Reihenfolge geändert werden, so dass das resultierende Diagramm besser gelesen werden kann.
Für Säulen- oder Balkendiagramme gibt es die Funktionen
fct_infreq()um die Levels in steigender Häufigkeit zu ordnen. Dazu benötigt man keine weiteren Argumente.Die Funktion
fct_rev()invertiert die Reihenfolge der Levels.
gss_cat |>
mutate(marital = marital |>
fct_infreq()) |>
ggplot(aes(marital)) +
geom_bar()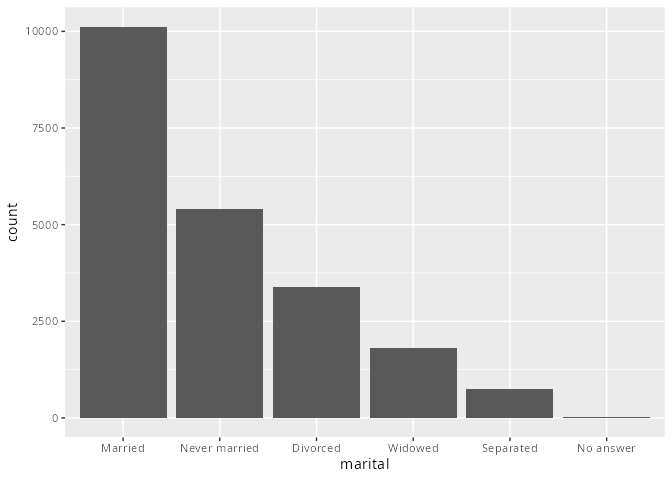
gss_cat |>
mutate(marital = marital |>
fct_infreq() |>
fct_rev()) |>
ggplot(aes(marital)) +
geom_bar()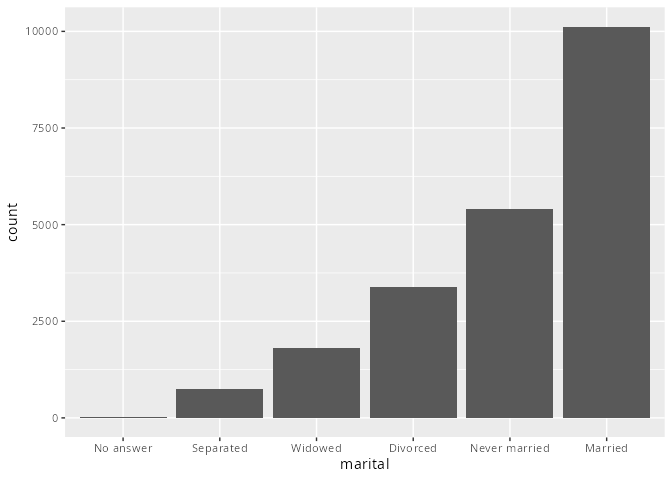
fct_rev() kann die Reihenfolge der Faktoren umgedreht werden.
15.3 Ändern der Levels
15.3.1 Levels Umbenennen
- Neben dem Ändern der Ordnung ist eine Änderung der Levels selbst oft wünschenswert.
- Mit der Funktion
fct_recode()können Levels umbenannt werden. - Im folgenden Beispiel sind die Level schlecht und nicht konsistent:
gss_cat |> count(partyid)# A tibble: 10 × 2
partyid n
<fct> <int>
1 No answer 154
2 Don't know 1
3 Other party 393
4 Strong republican 2314
5 Not str republican 3032
6 Ind,near rep 1791
7 Independent 4119
8 Ind,near dem 2499
9 Not str democrat 3690
10 Strong democrat 3490gss_cat |>
mutate(partyid = fct_recode(partyid,
"Republican, strong" = "Strong republican",
"Republican, weak" = "Not str republican",
"Democrat, weak" = "Not str democrat",
"Democrat, strong" = "Strong democrat",
"Independent, near rep" = "Ind,near rep",
"Independent, near dem" = "Ind,near dem"
)) |>
count(partyid)# A tibble: 10 × 2
partyid n
<fct> <int>
1 No answer 154
2 Don't know 1
3 Other party 393
4 Republican, strong 2314
5 Republican, weak 3032
6 Independent, near rep 1791
7 Independent 4119
8 Independent, near dem 2499
9 Democrat, weak 3690
10 Democrat, strong 349015.3.2 Levels Zusammenfassen
Sollen Levels zusammengefasst werden gibt es mehrere Möglichkeiten dies zu tun:
Mit der Funktion
fct_recode()kann ein neues Level für verschiedene alte Level angegeben werden.Bei der Funktion
fct_collapse()werden jeweils diverse alte Levels zu einem ‘kollabiert’ (siehe nächste Folie).Bei der Funktion
fct_lump(), werden dien=größten Levels behalten, wobein=ein (optionales) Argument ist. Die restlichen Levels werden zusammengefasst und bekommen alle die Ausprägungother.
Wird das Argument n= nicht angegeben, so werden so viele Level wie möglich zusammengefasst, unter der Bedingung, dass die Ausprägung other immer noch diejenige ist, die am wenigsten häufig auftritt.
gss_cat |>
mutate(partyid = fct_recode(partyid,
"Republican" = "Strong republican",
"Republican" = "Not str republican",
"Independent" = "Ind,near rep",
"Independent" = "Ind,near dem",
"Democrat" = "Not str democrat",
"Democrat" = "Strong democrat",
"Other" = "No answer",
"Other" = "Don't know",
"Other" = "Other party"
)) |>
count(partyid)# A tibble: 4 × 2
partyid n
<fct> <int>
1 Other 548
2 Republican 5346
3 Independent 8409
4 Democrat 7180# Beispiel fct_collapse():
gss_cat |>
mutate(partyid = fct_collapse(partyid,
other = c("No answer", "Don't know", "Other party"),
rep = c("Strong republican", "Not str republican"),
ind = c("Ind,near rep", "Independent", "Ind,near dem"),
dem = c("Not str democrat", "Strong democrat")
)) |>
count(partyid)# A tibble: 4 × 2
partyid n
<fct> <int>
1 other 548
2 rep 5346
3 ind 8409
4 dem 7180# Beispiele für fct_lump():
gss_cat |>
mutate(relig = fct_lump(relig)) |>
count(relig, sort = TRUE) # A tibble: 2 × 2
relig n
<fct> <int>
1 Protestant 10846
2 Other 10637gss_cat |>
mutate(relig = fct_lump(relig, n = 5)) |>
count(relig, sort = TRUE) # A tibble: 6 × 2
relig n
<fct> <int>
1 Protestant 10846
2 Catholic 5124
3 None 3523
4 Other 913
5 Christian 689
6 Jewish 388