In diesem Kapitel gehen wir von einem bereinigten Datensatz aus, der für die betrachteten Merkmale keine NAs mehr enthält.
Wir betrachten n Testpersonen v = 1, \cdots, n, die jeweils die Items i = 1, \cdots, m bearbeitet haben. Die Testantworten werden mit y_{vi} bezeichnet, das heißt die Testperson v hat das Item i mit y_{vi} beantwortet.
Ferner soll die Items derart kodiert sein, dass die Antwortmöglichkeiten für ein Item i zwischen 0 und einen maximalen Wert y_{\text{i, max}} liegen. Sollte das nicht der Fall, so müssen die Items umskaliert werden.
Der mittlere Itemwert eines Items i mit i = 1, \cdots, m ist das arithmetische Mittel der Antworten, gemittelt über alle n Testpersonen
\overline{y}_i = \frac{1}{n} \sum_{v=1}^n y_{vi} \quad \text{für} \quad i = 1, \cdots, m.
Berechnung spaltenweise (Mittelwert über alle Reihen)
Mit Hilfe der Funktion summarise() (bzw. summarize()) können Berechnungen spaltenweise, in diesem Fall also bezüglich eines Items gemacht werden. Da iwr das für alle Items gleichzeitig machen ist das Ergebnis eine neue Datentabelle.
Diese Tabelle ist ein wenig unübersichtlich. Mit Hilfe des Pivotierens aus Kapitel 4.3 können wir die obige Tabelle aber als eine lange Tabelle schreiben und bei Bedarf sortieren.
Der Zustimmungsindex (oder Schwierigkeitsindex) P_i eines Items i ist der Quotient aus der durchschnittlich erreichten Punktsumme aller n Testpersonen und der beim Item i maximal erreichbaren Punktsumme y_{\text{i, max}} multipliziert mit 100:
Sollte die Skala eines Items nicht bei 0 beginnen, so muss die Itemskala entsprechend umskaliert werden:
P_i = 100 \cdot \frac{\overline{y_i} - y_{i, \text{min}}} {y_{i, \text{ max}} - y_{i, \text{min}}} \quad \text{für} \quad i = 1, \cdots, m.
Dabei ist y_{i, \text{min}} der minimal mögliche Wert bevor die Skala umskaliert wird. Dann ist dann \overline{y_i} - y_{i, \text{min}} der mittlere Itemwert der umskalierten Items und y_{i, \text{ max}} - y_{i, \text{min}} der durch das Umskalieren neue maximale Wert der Items. Siehe dazu auch die Transformationsregel .
Die Bezeichnung Schwierigkeitsindex kommt aus der Pädagogik und bezieht sich auf Tests bei denen die Antworten richtig oder falsch sein können. Im Kontext von Umfragen, wie sie zum Beispiel in diesem Kurs gemacht werden, ist es sinnvoller von Zustimmungsindex zu sprechen.
Wir möchten nach Möglichkeit eine mittlere Zustimmung bei jedem Item haben, da dies zur besten Differenzierung führen kann.
5.3 Itemwertvarianz
Warum die Varianz der Items wichtig ist
Falls ein Item zwar einen angemessen mittleren Itemwert hat, aber alle Personen die gleiche Antwort gegeben haben, ist das Item zwar bezüglich der Zustimmung in Ordnung, aber nicht nützlich, um Individuen voneinander zu differenzieren.
WarnungItemvarianz
Unter der Itemvarianz versteht man ein Maß für die Differenzierungsfähigkeit eines Items i in der untersuchten Stichprobe:
Der Testwert Y_v für Person v ist die Summe der Werte y_{vi} der Items i=1, \cdots, m:
Y_v = \sum_{i=1}^m y_{vi}.
Bemerkungen:
Testwerte werden manchmal auch Summenwerte, Rohwerte oder Skalenwerte genannt.
Die Testwerte werdeb bezüglich eines Konstrukts berechnet.
Statt der Summe kann komplett analog auch der Mittelwert benutzt werden.
Beispiel: Testwerte
Berechnung zeilenweise (über selektierte Spalten)
testwerte<-umfrage|>rowwise()|>mutate(S_Summe =sum(c_across(starts_with("SE0"))), T_Summe =sum(c_across(starts_with("TE0"))))|>ungroup()|>select(S_Summe, T_Summe)# nur für die Übersichttestwerte
Testwert durch Addition muss nicht unbedingt sinnvoll sein.
Eindimensionalität sollte vorliegen.
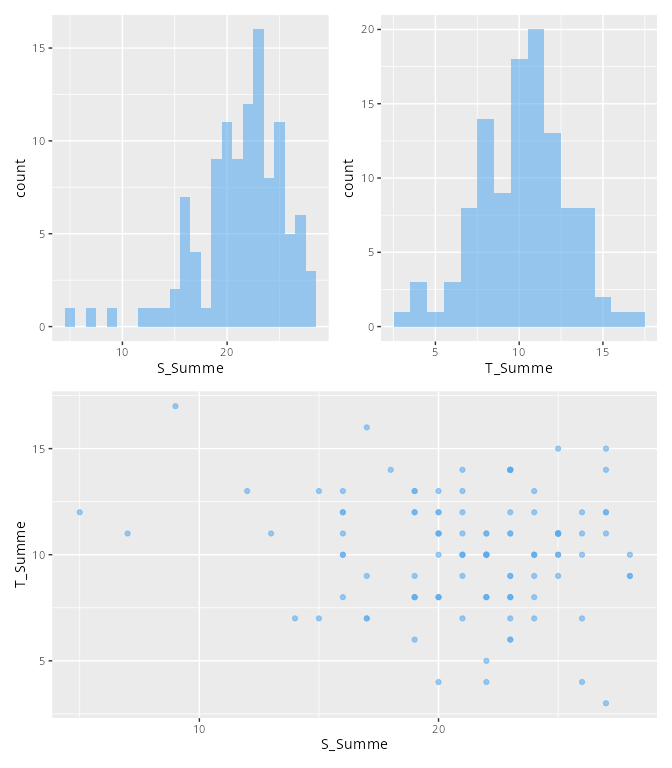
Darstellung der Testwerte über Histogramme (univariat) oder Streudiagramm (bivariat).
library(patchwork)g1<-testwerte|>ggplot(aes(x =S_Summe))+geom_histogram(alpha =0.6, fill ="steelblue2", binwidth=1)g2<-testwerte|>ggplot(aes(x =T_Summe))+geom_histogram(alpha =0.6, fill ="steelblue2", binwidth =1)g3<-testwerte|>ggplot(aes(x =S_Summe, y =T_Summe))+geom_point(alpha =0.6, color ="steelblue2")(g1|g2)/g3
5.4.1 Homogenitätsindex
WarnungMittlere Inter-Item Korrelation (MIC)
Die mittlere Inter-Item Korrelation gibt an, wie ähnlich (homogen) die Items sind. Sie wird als durchschnittliche paarweise Korrelation berechnet:
\mathrm{MIC} = \frac{2}{m(m-1)} \cdot \sum_{i < j} \mathrm{Cor}(y_i, y_j)
HinweisDaumenregel
Die mittlere Inter-Item Korrelation liegt typischerweise zwischen 0.2 und 0.4.
Min. 1st Qu. Median Mean 3rd Qu. Max.
-0.48336 -0.14551 0.07643 0.06992 0.22193 0.69104
5.5 Reliabilität & Cronbach’s \alpha – PI
5.5.1 Reliabilität & Cronbach’s \alpha
WarnungReliabilität
Die Messgenauigkeit/Reliabilität/Zuverlässigkeit einer Skala ist als Varianzverhältnis definiert:
\mathrm{Rel}(\overline{Y}) = \mathrm{Rel}\left(\frac{1}{m}\sum_{i=1}^m Y_i\right) =
\frac{\mathrm{Var}\left(\sum \tau_i\right)}{\mathrm{Var}\left(\sum Y_i\right)} \in [0, 1].
Schätzung von \mathrm{Rel} durch (Herleitung nach Bühner, 2021):
\alpha = \frac{m}{m-1}\left(1 - \frac{\sum \mathrm{Var}(Y_i)}{\mathrm{Var}(\sum Y_i)}\right)
= 2 \cdot \frac{m}{m-1}\frac{\sum \mathrm{Cov}_{i<j}(Y_i, Y_j)}{\mathrm{Var}(\sum Y_i)}.
HinweisInterpretation
Maßzahl für interne Konsistenz einer Skala
Wie stehen Fragen einer Skala miteinander in Beziehung?
5.5.2 Beispiel
Interne Konsistenz von Noten (Leistungsfähigkeit in Schule)
5.5.3 Cronbachs \alpha je Konstrukt & if item deleted
Mehrere Konstrukte in einer Umfrage:
Cronbachs \alpha je Konstrukt (nur die jeweiligen Items)
Messung der internen Konsistenz der Skalen (der Konstrukte)
Cronbach \alphaif item deleted:
Interne Konsistenz einzelner Items mit restlichen Items
Cronbach’s \alpha nach Weglassen des Items
Wert größer als für Gesamtkonstrukt: Item ggf. weglassen
A<-matrix(c(1,2,3, 1,2,3, 1,2,1), nrow =3)#psych::alpha(A)$alpha.drop$raw_alpha # Alpha für (Ph,D), (M,D) und (M,Ph)#psych::alpha(A)$total$raw_alpha # Alpha für alle drei Items
Prinzipiell gilt, dass man stets nur sinnvoll viele Nachkommastellen angeben sollte. Sämtliche Zahlen, die prinzipiell Nachkommastellen haben können, sollen nach APA (American Psychological Association) auf zwei Nachkommastellen gerundet werden. Dabei soll ein 0 vor dem Komma weggelassen werden.
# APA-konformes Runden geht so:library(weights)Zahlen<-c(-0.8, 1.456, 0.09, -3.4)rd(Zahlen, digits =2)
[1] "-.80" "1.46" ".09" "-3.40"
HinweisAusnahmen
Bei p-Werten sollte auf drei Nachkommastellen gerundet werden.
Moosbrugger, Helfried, und Augustin Kelava. 2020. Testtheorie und Fragebogenkonstruktion. 3. Aufl. Springer.