Das Merkmal X wird an n Merkmalsträgern gemessen und liegt in der Reihenfolge der Beobachtungen vor. Dies nennt man die Rohdaten (oder auch Urliste oder Primärdaten): (x_1, x_2, x_3, \cdots, x_n). Sortiert man die Rohdaten (auf- oder absteigend), so spricht man von einer Rangwertreihe (oder sortierte Rohdaten bzw. sortierte Urliste ) und schreibt (x_{[1]}, x_{[2]}, x_{[3]}, \cdots, x_{[n]}), wobei x_{[i]}, den Wert symbolisiert, der in der Rangwertreihe an i-ter Stelle steht.
Beispiel
# Eingabe der Rohdaten:(rohdaten<-c(19, 9, 9, 11, 7, 12))
[1] 19 9 9 11 7 12
# Erstellen der Rangwertreihe:(rangwertreihe<-sort(rohdaten))
[1] 7 9 9 11 12 19
# Bestimmen der Ränge mit R: (ties.method = "first")(raenge<-rank(rohdaten, ties.method ="first"))
[1] 6 2 3 4 1 5
# Bestimmen der Ränge mit R: (ties.method = "average")(raenge<-rank(rohdaten, ties.method ="average"))# Standard
[1] 6.0 2.5 2.5 4.0 1.0 5.0
Die Bildung der Ränge bedürfen einer Erklärung: Der durch die Funktion rank() angegebene Wert gibt an, an welcher Stelle der Eintrag eines Vektors stünde, wenn die Urliste sortiert wäre. Dabei gibt es mehrere Möglichkeiten, wie mit gleichen Werten umgegangen wird.
ties.method = "first" bedeutet, dass bei gleichen Werten der weiter vorne stehende den kleineren Wert bekommt. Im oberen Beispiel bekommt also die erste 9 der Urliste den Wert 2, da nur die 7 kleiner ist (diese bekommt den Wert 1). Die zweite 9 bekommt den Wert 3.
ties.method = "avarage" hingegen mittelt bei gleichen Werte. Möchte man diese rechnen nimmt man die Ränge aus der Methode ties.method = "first" und mittelt diese Ränge der gleichen Werte. Alle Werte bekommen dann diesen Rang. Im obigen Beispiel sind das bei der 9 die Ränge 2 und 3, so dass jede 9 den Rang \frac{1}{2}(2+3) = 2.5 bekommt.
Beide Methoden sind wichtig!
Die erstere wird zum Beispiel beim Erstellen der sortierten Urliste benutzt: Nimmt man das obige Beispiel, so ist x_1 = 19, x_2 = 9, x_3 =9, x_4=11, x_5=7 und x_6=12. Für die sortierte Urliste gilt: x_{[1]} = 7, x_{[2]} = 9, x_{[3]} =9 und so weiter. In den eckigen Klammern steht jeweils der Rang der Zahl (der Rang der 7 ist 1, der Rang der ersten 9ist 2, und so weiter).
Die zweite Methode wird Anwendung bei den Korrelationskoeffizienten finden.
Selbsttest: Ränge
Schwierigkeit: ★☆☆☆
Gegeben sind die folgenden Rohdaten
Rohdaten
8
12
12
16
8
12
16
11
first
average
Bestimmen Sie ohne R die Ränge der Rohdaten auf beide Methoden.
Bestimmen Sie nun mit R die Ränge der Rohdaten auf beide Methoden. Schreiben Sie die Rohdaten einmal in einen Vektor und bestimmen Sie danach die Ränge.
Rohdaten
8
12
12
16
8
12
16
11
first
1
4
5
7
2
6
8
3
average
1.5
5
5
7.5
1.5
5
7.5
3
Schwierigkeit: ★☆☆☆
Gegeben sind die folgenden Rohdaten
Rohdaten
11
14
13
14
13
13
10
10
first
average
Bestimmen Sie ohne R die Ränge der Rohdaten auf beide Methoden.
Bestimmen Sie nun mit R die Ränge der Rohdaten auf beide Methoden. Schreiben Sie die Rohdaten einmal in einen Vektor und bestimmen Sie danach die Ränge.
Rohdaten
11
14
13
14
13
13
10
10
first
3
7
4
8
5
6
1
2
average
3
7.5
5
7.5
5
5
1.5
1.5
Schwierigkeit: ★☆☆☆
Gegeben sind die folgenden Rohdaten
Rohdaten
1.4
1
1
1
1.7
1.5
1.7
1.5
first
average
Bestimmen Sie ohne R die Ränge der Rohdaten auf beide Methoden.
Bestimmen Sie nun mit R die Ränge der Rohdaten auf beide Methoden. Schreiben Sie die Rohdaten einmal in einen Vektor und bestimmen Sie danach die Ränge.
Rohdaten
1.4
1
1
1
1.7
1.5
1.7
1.5
first
4
1
2
3
7
5
8
6
average
4
2
2
2
7.5
5.5
7.5
5.5
Schwierigkeit: ★☆☆☆
Gegeben sind die folgenden Rohdaten
Rohdaten
0.14
0.16
0.16
0.11
0.15
0.11
0.14
0.15
first
average
Bestimmen Sie ohne R die Ränge der Rohdaten auf beide Methoden.
Bestimmen Sie nun mit R die Ränge der Rohdaten auf beide Methoden. Schreiben Sie die Rohdaten einmal in einen Vektor und bestimmen Sie danach die Ränge.
Rohdaten
0.14
0.16
0.16
0.11
0.15
0.11
0.14
0.15
first
3
7
8
1
5
2
4
6
average
3.5
7.5
7.5
1.5
5.5
1.5
3.5
5.5
Schwierigkeit: ★☆☆☆
Gegeben sind die folgenden Rohdaten
Rohdaten
11
9
9
8
11
13
11
13
first
average
Bestimmen Sie ohne R die Ränge der Rohdaten auf beide Methoden.
Bestimmen Sie nun mit R die Ränge der Rohdaten auf beide Methoden. Schreiben Sie die Rohdaten einmal in einen Vektor und bestimmen Sie danach die Ränge.
Rohdaten
11
9
9
8
11
13
11
13
first
4
2
3
1
5
7
6
8
average
5
2.5
2.5
1
5
7.5
5
7.5
Schwierigkeit: ★☆☆☆
Gegeben sind die folgenden Rohdaten
Rohdaten
800
1100
1100
800
800
1200
1300
1300
first
average
Bestimmen Sie ohne R die Ränge der Rohdaten auf beide Methoden.
Bestimmen Sie nun mit R die Ränge der Rohdaten auf beide Methoden. Schreiben Sie die Rohdaten einmal in einen Vektor und bestimmen Sie danach die Ränge.
Rohdaten
800
1100
1100
800
800
1200
1300
1300
first
1
4
5
2
3
6
7
8
average
2
4.5
4.5
2
2
6
7.5
7.5
Schwierigkeit: ★☆☆☆
Gegeben sind die folgenden Rohdaten
Rohdaten
0.1
0.08
0.09
0.1
0.09
0.12
0.12
0.1
first
average
Bestimmen Sie ohne R die Ränge der Rohdaten auf beide Methoden.
Bestimmen Sie nun mit R die Ränge der Rohdaten auf beide Methoden. Schreiben Sie die Rohdaten einmal in einen Vektor und bestimmen Sie danach die Ränge.
Rohdaten
0.1
0.08
0.09
0.1
0.09
0.12
0.12
0.1
first
4
1
2
5
3
7
8
6
average
5
1
2.5
5
2.5
7.5
7.5
5
Schwierigkeit: ★☆☆☆
Gegeben sind die folgenden Rohdaten
Rohdaten
17
9
17
17
14
15
9
17
first
average
Bestimmen Sie ohne R die Ränge der Rohdaten auf beide Methoden.
Bestimmen Sie nun mit R die Ränge der Rohdaten auf beide Methoden. Schreiben Sie die Rohdaten einmal in einen Vektor und bestimmen Sie danach die Ränge.
Rohdaten
17
9
17
17
14
15
9
17
first
5
1
6
7
3
4
2
8
average
6.5
1.5
6.5
6.5
3
4
1.5
6.5
Schwierigkeit: ★☆☆☆
Gegeben sind die folgenden Rohdaten
Rohdaten
0.9
0.9
1.1
1
1.2
1.1
0.9
1.2
first
average
Bestimmen Sie ohne R die Ränge der Rohdaten auf beide Methoden.
Bestimmen Sie nun mit R die Ränge der Rohdaten auf beide Methoden. Schreiben Sie die Rohdaten einmal in einen Vektor und bestimmen Sie danach die Ränge.
Rohdaten
0.9
0.9
1.1
1
1.2
1.1
0.9
1.2
first
1
2
5
4
7
6
3
8
average
2
2
5.5
4
7.5
5.5
2
7.5
Schwierigkeit: ★☆☆☆
Gegeben sind die folgenden Rohdaten
Rohdaten
130
90
130
90
120
120
80
90
first
average
Bestimmen Sie ohne R die Ränge der Rohdaten auf beide Methoden.
Bestimmen Sie nun mit R die Ränge der Rohdaten auf beide Methoden. Schreiben Sie die Rohdaten einmal in einen Vektor und bestimmen Sie danach die Ränge.
Rohdaten
130
90
130
90
120
120
80
90
first
7
2
8
3
5
6
1
4
average
7.5
3
7.5
3
5.5
5.5
1
3
Schwierigkeit: ★☆☆☆
Gegeben sind die folgenden Rohdaten
Rohdaten
13
17
13
16
13
8
13
16
first
average
Bestimmen Sie ohne R die Ränge der Rohdaten auf beide Methoden.
Bestimmen Sie nun mit R die Ränge der Rohdaten auf beide Methoden. Schreiben Sie die Rohdaten einmal in einen Vektor und bestimmen Sie danach die Ränge.
Rohdaten
13
17
13
16
13
8
13
16
first
2
8
3
6
4
1
5
7
average
3.5
8
3.5
6.5
3.5
1
3.5
6.5
Schwierigkeit: ★☆☆☆
Gegeben sind die folgenden Rohdaten
Rohdaten
12
10
9
14
12
10
9
9
first
average
Bestimmen Sie ohne R die Ränge der Rohdaten auf beide Methoden.
Bestimmen Sie nun mit R die Ränge der Rohdaten auf beide Methoden. Schreiben Sie die Rohdaten einmal in einen Vektor und bestimmen Sie danach die Ränge.
Rohdaten
12
10
9
14
12
10
9
9
first
6
4
1
8
7
5
2
3
average
6.5
4.5
2
8
6.5
4.5
2
2
9.1 Diskretes Merkmal
9.1.1 Häufigkeiten
WarnungDefinition: Absolute und relative Häufigkeit
Gegeben sind n Elemente. Es wird ausgezählt wie häufig jede Ausprägung a_j mit j = 1, 2, \cdots, k unter diesen n Elementen vorkommt. Diese Anzahl bezeichnet man als absolute Häufigkeit der Ausprägung a_j und schreibt h(a_j) = h_j. Die absolute Häufigkeit bezogen auf die Gesamtzahl n heißt relative Häufigkeit und man schreibt f(a_j) = f_j = \frac{h_j}{n}.
Beispiel
Im folgenden Beispiel sind insgesamt 25 Elemente, den Rohdaten, in einem Vektor X gegeben.
Für absolute und relative Häufigkeiten muss das Merkmal lediglich diskret sein, das Skalenniveau spielt im Moment noch keine Rolle, da man nominal-, ordinal- und kardinalskalierte Merkmale auszählen kann.
WarnungDefinition: Kumulierte absolute und kumulierte relative Häufigkeit
Sei X ein diskretes, mindestens ordinales Merkmal mit den sortierten Ausprägungen a_j mit j = 1, 2, \cdots, k, so dass a_1 < a_2 < \cdots < a_k ist. Seien ferner h(a_j) und f(a_j) die absoluten bzw. relativen Häufigkeiten, dann nennt man die Größen
Wie man an den beiden obigen Beispielen sieht, ist es für die Häufigkeiten nur wichtig, dass die Merkmale diskret sind. Die Merkmale müssen nicht notwendigerweise kategorial sein, sondern können auch kardinal sein, wie das letzte Beispiel zeigt. Für die kumulierten (relativen) Häufigkeiten benötigt man ein mindestens ordinal skaliertes Merkmal.
Selbsttest: Häufigkeiten
Schwierigkeit: ★★☆☆
Gegeben sind die folgenden Rohdaten:
x_{1}
x_{2}
x_{3}
x_{4}
x_{5}
x_{6}
x_{7}
x_{8}
x_{9}
x_{10}
6
4
5
4
4
3
2
5
4
6
x_{11}
x_{12}
x_{13}
x_{14}
x_{15}
x_{16}
x_{17}
x_{18}
x_{19}
x_{20}
5
6
4
4
6
5
4
5
4
4
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
Ausprägung
abs. Häufigkeit
kum. abs. Häufigkeit
rel. Häufigkeit
kum. rel. Häufigkeit
i
1
2
3
4
5
a_i
2
3
4
5
6
h_i
1
1
9
5
4
H_i
1
2
11
16
20
f_i
0.05
0.05
0.45
0.25
0.2
F_i
0.05
0.1
0.55
0.8
1
Schwierigkeit: ★★☆☆
Gegeben sind die folgenden Rohdaten:
x_{1}
x_{2}
x_{3}
x_{4}
x_{5}
x_{6}
x_{7}
x_{8}
x_{9}
x_{10}
5
4
5
8
3
3
5
4
3
5
x_{11}
x_{12}
x_{13}
x_{14}
x_{15}
x_{16}
x_{17}
x_{18}
x_{19}
x_{20}
8
3
0
3
3
8
5
8
4
4
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
Ausprägung
abs. Häufigkeit
kum. abs. Häufigkeit
rel. Häufigkeit
kum. rel. Häufigkeit
i
1
2
3
4
5
a_i
0
3
4
5
8
h_i
1
6
4
5
4
H_i
1
7
11
16
20
f_i
0.05
0.3
0.2
0.25
0.2
F_i
0.05
0.35
0.55
0.8
1
Schwierigkeit: ★★☆☆
Gegeben sind die folgenden Rohdaten:
x_{1}
x_{2}
x_{3}
x_{4}
x_{5}
x_{6}
x_{7}
x_{8}
x_{9}
x_{10}
80
40
10
10
10
10
60
10
10
80
x_{11}
x_{12}
x_{13}
x_{14}
x_{15}
x_{16}
x_{17}
x_{18}
x_{19}
x_{20}
80
10
30
60
40
60
80
60
80
40
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
Ausprägung
abs. Häufigkeit
kum. abs. Häufigkeit
rel. Häufigkeit
kum. rel. Häufigkeit
i
1
2
3
4
5
a_i
10
30
40
60
80
h_i
7
1
3
4
5
H_i
7
8
11
15
20
f_i
0.35
0.05
0.15
0.2
0.25
F_i
0.35
0.4
0.55
0.75
1
Schwierigkeit: ★★☆☆
Gegeben sind die folgenden Rohdaten:
x_{1}
x_{2}
x_{3}
x_{4}
x_{5}
x_{6}
x_{7}
x_{8}
x_{9}
x_{10}
0.03
0.04
0.03
0
0.03
0.03
0.04
0.04
0.02
0.02
x_{11}
x_{12}
x_{13}
x_{14}
x_{15}
x_{16}
x_{17}
x_{18}
x_{19}
x_{20}
0
0.06
0.03
0.03
0.04
0.02
0.04
0.04
0.02
0.03
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
Ausprägung
abs. Häufigkeit
kum. abs. Häufigkeit
rel. Häufigkeit
kum. rel. Häufigkeit
i
1
2
3
4
5
a_i
0
0.02
0.03
0.04
0.06
h_i
2
4
7
6
1
H_i
2
6
13
19
20
f_i
0.1
0.2
0.35
0.3
0.05
F_i
0.1
0.3
0.65
0.95
1
Schwierigkeit: ★★☆☆
Gegeben sind die folgenden Rohdaten:
x_{1}
x_{2}
x_{3}
x_{4}
x_{5}
x_{6}
x_{7}
x_{8}
x_{9}
x_{10}
0.03
0.02
0
0.03
0.02
0.05
0.03
0.03
0.09
0.03
x_{11}
x_{12}
x_{13}
x_{14}
x_{15}
x_{16}
x_{17}
x_{18}
x_{19}
x_{20}
0
0.02
0.05
0.09
0
0.02
0.03
0.02
0.09
0
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
Ausprägung
abs. Häufigkeit
kum. abs. Häufigkeit
rel. Häufigkeit
kum. rel. Häufigkeit
i
1
2
3
4
5
a_i
0
0.02
0.03
0.05
0.09
h_i
4
5
6
2
3
H_i
4
9
15
17
20
f_i
0.2
0.25
0.3
0.1
0.15
F_i
0.2
0.45
0.75
0.85
1
Schwierigkeit: ★★☆☆
Gegeben sind die folgenden Rohdaten:
x_{1}
x_{2}
x_{3}
x_{4}
x_{5}
x_{6}
x_{7}
x_{8}
x_{9}
x_{10}
0.09
0.09
0.03
0.03
0.09
0.01
0
0.06
0
0.09
x_{11}
x_{12}
x_{13}
x_{14}
x_{15}
x_{16}
x_{17}
x_{18}
x_{19}
x_{20}
0.01
0.06
0
0.06
0.03
0.06
0.06
0.03
0.01
0.03
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
Ausprägung
abs. Häufigkeit
kum. abs. Häufigkeit
rel. Häufigkeit
kum. rel. Häufigkeit
i
1
2
3
4
5
a_i
0
0.01
0.03
0.06
0.09
h_i
3
3
5
5
4
H_i
3
6
11
16
20
f_i
0.15
0.15
0.25
0.25
0.2
F_i
0.15
0.3
0.55
0.8
1
Schwierigkeit: ★★☆☆
Gegeben sind die folgenden Rohdaten:
x_{1}
x_{2}
x_{3}
x_{4}
x_{5}
x_{6}
x_{7}
x_{8}
x_{9}
x_{10}
0
9000
9000
0
9000
2000
2000
2000
8000
9000
x_{11}
x_{12}
x_{13}
x_{14}
x_{15}
x_{16}
x_{17}
x_{18}
x_{19}
x_{20}
9000
9000
9000
5000
9000
0
9000
9000
9000
8000
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
Ausprägung
abs. Häufigkeit
kum. abs. Häufigkeit
rel. Häufigkeit
kum. rel. Häufigkeit
i
1
2
3
4
5
a_i
0
2000
5000
8000
9000
h_i
3
3
1
2
11
H_i
3
6
7
9
20
f_i
0.15
0.15
0.05
0.1
0.55
F_i
0.15
0.3
0.35
0.45
1
Schwierigkeit: ★★☆☆
Gegeben sind die folgenden Rohdaten:
x_{1}
x_{2}
x_{3}
x_{4}
x_{5}
x_{6}
x_{7}
x_{8}
x_{9}
x_{10}
0.4
0.9
0.3
0.4
0.9
0.3
0
0.9
0.4
0.2
x_{11}
x_{12}
x_{13}
x_{14}
x_{15}
x_{16}
x_{17}
x_{18}
x_{19}
x_{20}
0.9
0
0.3
0.4
0.3
0.3
0.4
0.9
0.3
0.3
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
Ausprägung
abs. Häufigkeit
kum. abs. Häufigkeit
rel. Häufigkeit
kum. rel. Häufigkeit
i
1
2
3
4
5
a_i
0
0.2
0.3
0.4
0.9
h_i
2
1
7
5
5
H_i
2
3
10
15
20
f_i
0.1
0.05
0.35
0.25
0.25
F_i
0.1
0.15
0.5
0.75
1
Schwierigkeit: ★★☆☆
Gegeben sind die folgenden Rohdaten:
x_{1}
x_{2}
x_{3}
x_{4}
x_{5}
x_{6}
x_{7}
x_{8}
x_{9}
x_{10}
0.5
0.8
0.5
0.9
0.8
0.5
0.8
0.8
0.7
0.9
x_{11}
x_{12}
x_{13}
x_{14}
x_{15}
x_{16}
x_{17}
x_{18}
x_{19}
x_{20}
0.3
0.3
0.7
0.8
0.7
0.9
0.8
0.9
0.7
0.8
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
Ausprägung
abs. Häufigkeit
kum. abs. Häufigkeit
rel. Häufigkeit
kum. rel. Häufigkeit
i
1
2
3
4
5
a_i
0.3
0.5
0.7
0.8
0.9
h_i
2
3
4
7
4
H_i
2
5
9
16
20
f_i
0.1
0.15
0.2
0.35
0.2
F_i
0.1
0.25
0.45
0.8
1
Schwierigkeit: ★★☆☆
Gegeben sind die folgenden Rohdaten:
x_{1}
x_{2}
x_{3}
x_{4}
x_{5}
x_{6}
x_{7}
x_{8}
x_{9}
x_{10}
0
0
0
6
4
0
6
0
6
0
x_{11}
x_{12}
x_{13}
x_{14}
x_{15}
x_{16}
x_{17}
x_{18}
x_{19}
x_{20}
6
0
0
1
0
1
8
8
6
1
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
Ausprägung
abs. Häufigkeit
kum. abs. Häufigkeit
rel. Häufigkeit
kum. rel. Häufigkeit
i
1
2
3
4
5
a_i
0
1
4
6
8
h_i
9
3
1
5
2
H_i
9
12
13
18
20
f_i
0.45
0.15
0.05
0.25
0.1
F_i
0.45
0.6
0.65
0.9
1
Schwierigkeit: ★★☆☆
Gegeben sind die folgenden Rohdaten:
x_{1}
x_{2}
x_{3}
x_{4}
x_{5}
x_{6}
x_{7}
x_{8}
x_{9}
x_{10}
300
500
500
600
600
300
300
700
300
300
x_{11}
x_{12}
x_{13}
x_{14}
x_{15}
x_{16}
x_{17}
x_{18}
x_{19}
x_{20}
300
300
300
0
500
600
600
600
600
600
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
Ausprägung
abs. Häufigkeit
kum. abs. Häufigkeit
rel. Häufigkeit
kum. rel. Häufigkeit
i
1
2
3
4
5
a_i
0
300
500
600
700
h_i
1
8
3
7
1
H_i
1
9
12
19
20
f_i
0.05
0.4
0.15
0.35
0.05
F_i
0.05
0.45
0.6
0.95
1
Schwierigkeit: ★★☆☆
Gegeben sind die folgenden Rohdaten:
x_{1}
x_{2}
x_{3}
x_{4}
x_{5}
x_{6}
x_{7}
x_{8}
x_{9}
x_{10}
3000
1000
5000
1000
5000
5000
7000
0
5000
5000
x_{11}
x_{12}
x_{13}
x_{14}
x_{15}
x_{16}
x_{17}
x_{18}
x_{19}
x_{20}
3000
5000
1000
5000
7000
5000
3000
5000
5000
5000
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
Ausprägung
abs. Häufigkeit
kum. abs. Häufigkeit
rel. Häufigkeit
kum. rel. Häufigkeit
i
1
2
3
4
5
a_i
0
1000
3000
5000
7000
h_i
1
3
3
11
2
H_i
1
4
7
18
20
f_i
0.05
0.15
0.15
0.55
0.1
F_i
0.05
0.2
0.35
0.9
1
Schwierigkeit: ★★☆☆
Gegeben sind die folgenden Rohdaten:
x_{1}
x_{2}
x_{3}
x_{4}
x_{5}
x_{6}
x_{7}
x_{8}
x_{9}
x_{10}
4000
4000
5000
5000
3000
3000
2000
4000
2000
4000
x_{11}
x_{12}
x_{13}
x_{14}
x_{15}
x_{16}
x_{17}
x_{18}
x_{19}
x_{20}
4000
4000
3000
8000
8000
8000
8000
5000
8000
5000
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
Ausprägung
abs. Häufigkeit
kum. abs. Häufigkeit
rel. Häufigkeit
kum. rel. Häufigkeit
i
1
2
3
4
5
a_i
2000
3000
4000
5000
8000
h_i
2
3
6
4
5
H_i
2
5
11
15
20
f_i
0.1
0.15
0.3
0.2
0.25
F_i
0.1
0.25
0.55
0.75
1
Schwierigkeit: ★★☆☆
Gegeben sind die folgenden Rohdaten:
x_{1}
x_{2}
x_{3}
x_{4}
x_{5}
x_{6}
x_{7}
x_{8}
x_{9}
x_{10}
0.01
0.09
0.08
0.01
0.08
0.01
0
0
0.02
0.09
x_{11}
x_{12}
x_{13}
x_{14}
x_{15}
x_{16}
x_{17}
x_{18}
x_{19}
x_{20}
0.02
0
0.09
0
0.08
0.09
0.08
0.02
0.01
0.01
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
Ausprägung
abs. Häufigkeit
kum. abs. Häufigkeit
rel. Häufigkeit
kum. rel. Häufigkeit
i
1
2
3
4
5
a_i
0
0.01
0.02
0.08
0.09
h_i
4
5
3
4
4
H_i
4
9
12
16
20
f_i
0.2
0.25
0.15
0.2
0.2
F_i
0.2
0.45
0.6
0.8
1
Schwierigkeit: ★★☆☆
Gegeben sind die folgenden Rohdaten:
x_{1}
x_{2}
x_{3}
x_{4}
x_{5}
x_{6}
x_{7}
x_{8}
x_{9}
x_{10}
8000
9000
7000
5000
8000
9000
9000
7000
5000
5000
x_{11}
x_{12}
x_{13}
x_{14}
x_{15}
x_{16}
x_{17}
x_{18}
x_{19}
x_{20}
5000
9000
2000
9000
9000
9000
9000
9000
2000
9000
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
Ausprägung
abs. Häufigkeit
kum. abs. Häufigkeit
rel. Häufigkeit
kum. rel. Häufigkeit
i
1
2
3
4
5
a_i
2000
5000
7000
8000
9000
h_i
2
4
2
2
10
H_i
2
6
8
10
20
f_i
0.1
0.2
0.1
0.1
0.5
F_i
0.1
0.3
0.4
0.5
1
Schwierigkeit: ★★☆☆
Gegeben sind die folgenden Rohdaten:
x_{1}
x_{2}
x_{3}
x_{4}
x_{5}
x_{6}
x_{7}
x_{8}
x_{9}
x_{10}
0.2
0.5
0.9
0.9
0.3
0.9
0.2
0.7
0.7
0.2
x_{11}
x_{12}
x_{13}
x_{14}
x_{15}
x_{16}
x_{17}
x_{18}
x_{19}
x_{20}
0.9
0.2
0.7
0.2
0.2
0.9
0.9
0.9
0.2
0.5
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
Ausprägung
abs. Häufigkeit
kum. abs. Häufigkeit
rel. Häufigkeit
kum. rel. Häufigkeit
i
1
2
3
4
5
a_i
0.2
0.3
0.5
0.7
0.9
h_i
7
1
2
3
7
H_i
7
8
10
13
20
f_i
0.35
0.05
0.1
0.15
0.35
F_i
0.35
0.4
0.5
0.65
1
Schwierigkeit: ★★☆☆
Gegeben sind die folgenden Rohdaten:
x_{1}
x_{2}
x_{3}
x_{4}
x_{5}
x_{6}
x_{7}
x_{8}
x_{9}
x_{10}
0.04
0.09
0.03
0.04
0.09
0.03
0.05
0.05
0.01
0.03
x_{11}
x_{12}
x_{13}
x_{14}
x_{15}
x_{16}
x_{17}
x_{18}
x_{19}
x_{20}
0.05
0.05
0.01
0.09
0.05
0.09
0.05
0.05
0.03
0.03
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
Ausprägung
abs. Häufigkeit
kum. abs. Häufigkeit
rel. Häufigkeit
kum. rel. Häufigkeit
i
1
2
3
4
5
a_i
0.01
0.03
0.04
0.05
0.09
h_i
2
5
2
7
4
H_i
2
7
9
16
20
f_i
0.1
0.25
0.1
0.35
0.2
F_i
0.1
0.35
0.45
0.8
1
Schwierigkeit: ★★☆☆
Gegeben sind die folgenden Rohdaten:
x_{1}
x_{2}
x_{3}
x_{4}
x_{5}
x_{6}
x_{7}
x_{8}
x_{9}
x_{10}
0.08
0.04
0.04
0.06
0.04
0.06
0.04
0.04
0
0.06
x_{11}
x_{12}
x_{13}
x_{14}
x_{15}
x_{16}
x_{17}
x_{18}
x_{19}
x_{20}
0.01
0.01
0.01
0.01
0.01
0.08
0
0.01
0.01
0
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
Ausprägung
abs. Häufigkeit
kum. abs. Häufigkeit
rel. Häufigkeit
kum. rel. Häufigkeit
i
1
2
3
4
5
a_i
0
0.01
0.04
0.06
0.08
h_i
3
7
5
3
2
H_i
3
10
15
18
20
f_i
0.15
0.35
0.25
0.15
0.1
F_i
0.15
0.5
0.75
0.9
1
Schwierigkeit: ★★☆☆
Gegeben sind die folgenden Rohdaten:
x_{1}
x_{2}
x_{3}
x_{4}
x_{5}
x_{6}
x_{7}
x_{8}
x_{9}
x_{10}
0.05
0.05
0.06
0.06
0.05
0.06
0.06
0.08
0.08
0.05
x_{11}
x_{12}
x_{13}
x_{14}
x_{15}
x_{16}
x_{17}
x_{18}
x_{19}
x_{20}
0
0
0.02
0.05
0.08
0.08
0
0.06
0.05
0
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
Ausprägung
abs. Häufigkeit
kum. abs. Häufigkeit
rel. Häufigkeit
kum. rel. Häufigkeit
i
1
2
3
4
5
a_i
0
0.02
0.05
0.06
0.08
h_i
4
1
6
5
4
H_i
4
5
11
16
20
f_i
0.2
0.05
0.3
0.25
0.2
F_i
0.2
0.25
0.55
0.8
1
Schwierigkeit: ★★☆☆
Gegeben sind die folgenden Rohdaten:
x_{1}
x_{2}
x_{3}
x_{4}
x_{5}
x_{6}
x_{7}
x_{8}
x_{9}
x_{10}
8000
6000
8000
8000
9000
4000
9000
2000
8000
6000
x_{11}
x_{12}
x_{13}
x_{14}
x_{15}
x_{16}
x_{17}
x_{18}
x_{19}
x_{20}
2000
2000
6000
6000
2000
2000
8000
8000
2000
6000
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
Ausprägung
abs. Häufigkeit
kum. abs. Häufigkeit
rel. Häufigkeit
kum. rel. Häufigkeit
i
1
2
3
4
5
a_i
2000
4000
6000
8000
9000
h_i
6
1
5
6
2
H_i
6
7
12
18
20
f_i
0.3
0.05
0.25
0.3
0.1
F_i
0.3
0.35
0.6
0.9
1
Schwierigkeit: ★☆☆☆
Gegeben sind die kumulierten relativen Häufigkeiten von 50 Beobachtungen. Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
6
a_i
0
3000
6000
9000
12000
18000
H_i
H_i
f_i
F_i
0.14
0.32
0.68
0.72
0.96
1
i
1
2
3
4
5
6
a_i
0
3000
6000
9000
12000
18000
h_i
7
9
18
2
12
2
H_i
7
16
34
36
48
50
f_i
0.14
0.18
0.36
0.04
0.24
0.04
F_i
0.14
0.32
0.68
0.72
0.96
1
Schwierigkeit: ★★☆☆
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
6
a_i
0
60000
120000
180000
240000
480000
h_i
76
H_i
184
424
500
f_i
0.086
0.258
F_i
0.396
i
1
2
3
4
5
6
a_i
0
60000
120000
180000
240000
480000
h_i
43
141
14
129
97
76
H_i
43
184
198
327
424
500
f_i
0.086
0.282
0.028
0.258
0.194
0.152
F_i
0.086
0.368
0.396
0.654
0.848
1
Schwierigkeit: ★☆☆☆
Gegeben sind die kumulierten relativen Häufigkeiten von 25 Beobachtungen. Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
6
a_i
0
4000
6000
8000
14000
18000
H_i
H_i
f_i
F_i
0.04
0.2
0.44
0.6
0.76
1
i
1
2
3
4
5
6
a_i
0
4000
6000
8000
14000
18000
h_i
1
4
6
4
4
6
H_i
1
5
11
15
19
25
f_i
0.04
0.16
0.24
0.16
0.16
0.24
F_i
0.04
0.2
0.44
0.6
0.76
1
Schwierigkeit: ★☆☆☆
Gegeben sind die relative Häufigkeiten von 20 ” Beobachtungen. Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
6
a_i
10000
15000
20000
30000
35000
45000
H_i
H_i
f_i
0.15
0.15
0.05
0.2
0.3
0.15
F_i
i
1
2
3
4
5
6
a_i
10000
15000
20000
30000
35000
45000
h_i
3
3
1
4
6
3
H_i
3
6
7
11
17
20
f_i
0.15
0.15
0.05
0.2
0.3
0.15
F_i
0.15
0.3
0.35
0.55
0.85
1
Schwierigkeit: ★☆☆☆
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
6
a_i
300
600
900
1200
1800
2100
h_i
H_i
6
18
28
34
43
50
f_i
F_i
i
1
2
3
4
5
6
a_i
300
600
900
1200
1800
2100
h_i
6
12
10
6
9
7
H_i
6
18
28
34
43
50
f_i
0.12
0.24
0.2
0.12
0.18
0.14
F_i
0.12
0.36
0.56
0.68
0.86
1
Schwierigkeit: ★★☆☆
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
6
a_i
700
2100
2800
3500
4900
6300
h_i
22
61
H_i
139
f_i
0.06
F_i
0.24
0.53
i
1
2
3
4
5
6
a_i
700
2100
2800
3500
4900
6300
h_i
48
12
46
22
11
61
H_i
48
60
106
128
139
200
f_i
0.24
0.06
0.23
0.11
0.055
0.305
F_i
0.24
0.3
0.53
0.64
0.695
1
Schwierigkeit: ★☆☆☆
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
6
a_i
8000
16000
20000
24000
32000
36000
h_i
H_i
4
28
51
56
94
100
f_i
F_i
i
1
2
3
4
5
6
a_i
8000
16000
20000
24000
32000
36000
h_i
4
24
23
5
38
6
H_i
4
28
51
56
94
100
f_i
0.04
0.24
0.23
0.05
0.38
0.06
F_i
0.04
0.28
0.51
0.56
0.94
1
Schwierigkeit: ★☆☆☆
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
6
a_i
0
1000
2000
4000
6000
9000
h_i
H_i
23
36
58
61
97
100
f_i
F_i
i
1
2
3
4
5
6
a_i
0
1000
2000
4000
6000
9000
h_i
23
13
22
3
36
3
H_i
23
36
58
61
97
100
f_i
0.23
0.13
0.22
0.03
0.36
0.03
F_i
0.23
0.36
0.58
0.61
0.97
1
Schwierigkeit: ★☆☆☆
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
6
a_i
0
4000
16000
20000
28000
32000
h_i
H_i
1
9
34
67
74
100
f_i
F_i
i
1
2
3
4
5
6
a_i
0
4000
16000
20000
28000
32000
h_i
1
8
25
33
7
26
H_i
1
9
34
67
74
100
f_i
0.01
0.08
0.25
0.33
0.07
0.26
F_i
0.01
0.09
0.34
0.67
0.74
1
Schwierigkeit: ★★☆☆
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
6
a_i
0.2
0.3
0.4
0.5
0.6
0.9
h_i
9
141
H_i
859
f_i
0.258
F_i
0.181
0.592
i
1
2
3
4
5
6
a_i
0.2
0.3
0.4
0.5
0.6
0.9
h_i
181
258
153
9
258
141
H_i
181
439
592
601
859
1000
f_i
0.181
0.258
0.153
0.009
0.258
0.141
F_i
0.181
0.439
0.592
0.601
0.859
1
Schwierigkeit: ★☆☆☆
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
6
a_i
0
16
40
48
64
72
h_i
10
5
11
10
8
6
H_i
f_i
F_i
i
1
2
3
4
5
6
a_i
0
16
40
48
64
72
h_i
10
5
11
10
8
6
H_i
10
15
26
36
44
50
f_i
0.2
0.1
0.22
0.2
0.16
0.12
F_i
0.2
0.3
0.52
0.72
0.88
1
Schwierigkeit: ★★☆☆
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
6
a_i
80000
160000
240000
400000
640000
720000
h_i
50
H_i
25
150
200
f_i
0.015
0.36
F_i
0.185
i
1
2
3
4
5
6
a_i
80000
160000
240000
400000
640000
720000
h_i
3
22
12
72
41
50
H_i
3
25
37
109
150
200
f_i
0.015
0.11
0.06
0.36
0.205
0.25
F_i
0.015
0.125
0.185
0.545
0.75
1
Schwierigkeit: ★☆☆☆
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
6
a_i
0.4
1.2
1.6
2.4
3.2
3.6
h_i
57
37
175
117
63
51
H_i
f_i
F_i
i
1
2
3
4
5
6
a_i
0.4
1.2
1.6
2.4
3.2
3.6
h_i
57
37
175
117
63
51
H_i
57
94
269
386
449
500
f_i
0.114
0.074
0.35
0.234
0.126
0.102
F_i
0.114
0.188
0.538
0.772
0.898
1
Schwierigkeit: ★☆☆☆
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
6
a_i
18
27
36
54
72
81
h_i
3
2
1
5
5
4
H_i
f_i
F_i
i
1
2
3
4
5
6
a_i
18
27
36
54
72
81
h_i
3
2
1
5
5
4
H_i
3
5
6
11
16
20
f_i
0.15
0.1
0.05
0.25
0.25
0.2
F_i
0.15
0.25
0.3
0.55
0.8
1
Schwierigkeit: ★★☆☆
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
6
a_i
2
6
8
12
14
18
h_i
2
H_i
7
23
25
f_i
0.2
0.04
F_i
0.48
i
1
2
3
4
5
6
a_i
2
6
8
12
14
18
h_i
5
2
5
1
10
2
H_i
5
7
12
13
23
25
f_i
0.2
0.08
0.2
0.04
0.4
0.08
F_i
0.2
0.28
0.48
0.52
0.92
1
Schwierigkeit: ★★☆☆
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
6
a_i
0
5000
15000
35000
40000
45000
h_i
19
H_i
29
81
100
f_i
0.22
0.21
F_i
0.5
i
1
2
3
4
5
6
a_i
0
5000
15000
35000
40000
45000
h_i
22
7
21
21
10
19
H_i
22
29
50
71
81
100
f_i
0.22
0.07
0.21
0.21
0.1
0.19
F_i
0.22
0.29
0.5
0.71
0.81
1
Schwierigkeit: ★☆☆☆
Gegeben sind die kumulierten relativen Häufigkeiten von 100 Beobachtungen. Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
6
a_i
0
0.2
0.4
0.6
0.8
1.6
H_i
H_i
f_i
F_i
0.17
0.29
0.35
0.43
0.54
1
i
1
2
3
4
5
6
a_i
0
0.2
0.4
0.6
0.8
1.6
h_i
17
12
6
8
11
46
H_i
17
29
35
43
54
100
f_i
0.17
0.12
0.06
0.08
0.11
0.46
F_i
0.17
0.29
0.35
0.43
0.54
1
Schwierigkeit: ★★☆☆
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
6
a_i
40
60
80
140
160
180
h_i
42
134
H_i
366
f_i
0.122
F_i
0.242
0.542
i
1
2
3
4
5
6
a_i
40
60
80
140
160
180
h_i
121
61
89
42
53
134
H_i
121
182
271
313
366
500
f_i
0.242
0.122
0.178
0.084
0.106
0.268
F_i
0.242
0.364
0.542
0.626
0.732
1
Schwierigkeit: ★☆☆☆
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
6
a_i
0
0.01
0.04
0.06
0.08
0.09
h_i
H_i
45
61
108
154
185
200
f_i
F_i
i
1
2
3
4
5
6
a_i
0
0.01
0.04
0.06
0.08
0.09
h_i
45
16
47
46
31
15
H_i
45
61
108
154
185
200
f_i
0.225
0.08
0.235
0.23
0.155
0.075
F_i
0.225
0.305
0.54
0.77
0.925
1
Schwierigkeit: ★☆☆☆
Vervollständigen Sie die folgende Häufigkeitstabelle:
i
1
2
3
4
5
6
a_i
0
0.4
0.6
0.8
1.2
1.4
h_i
H_i
57
66
129
159
183
200
f_i
F_i
i
1
2
3
4
5
6
a_i
0
0.4
0.6
0.8
1.2
1.4
h_i
57
9
63
30
24
17
H_i
57
66
129
159
183
200
f_i
0.285
0.045
0.315
0.15
0.12
0.085
F_i
0.285
0.33
0.645
0.795
0.915
1
9.1.2 Diskretes Merkmal: Darstellung
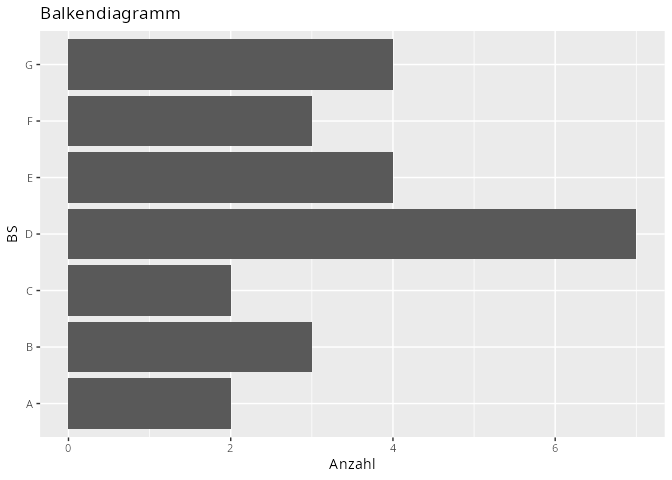
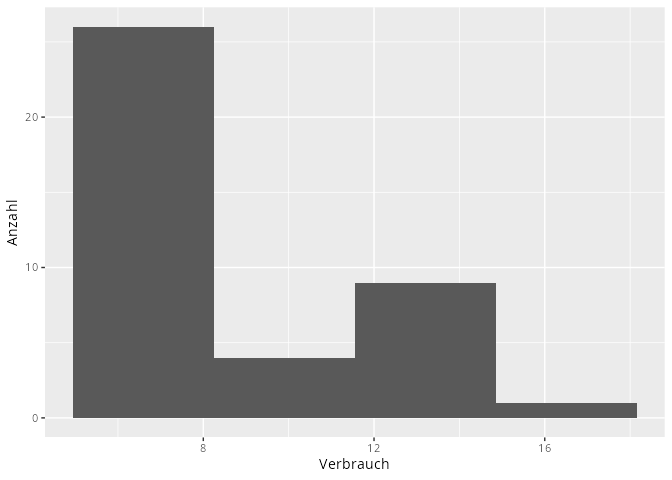
Ein (einzelnes) diskretes Merkmal stellt man in der Regel als Balkendiagramm oder Säulendiagramm dar.
Abbildung 9.1: Balkendiagramm
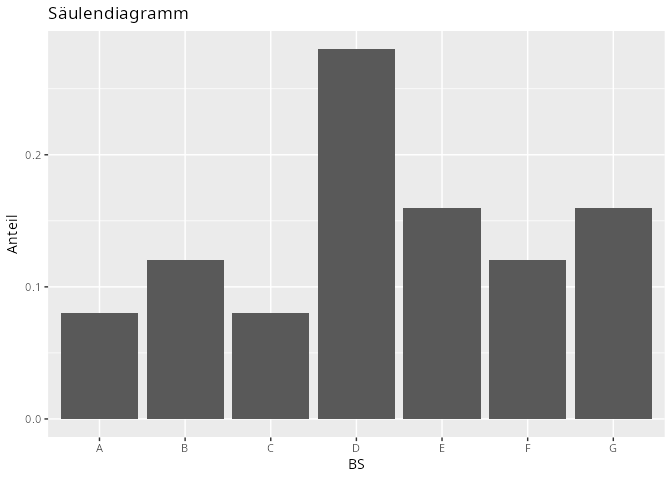
Abbildung 9.2: Säulendiagramm: durch die Funktion after_stat() wird nicht die absolute Anzahl, sondern der Anteil angezeigt.
X.tib<-tibble(BS =X)# X # tibble() erzeugt eine DatentabelleX.tib|>ggplot(aes(y =BS))+geom_bar(fill ="steelblue2", color ="gray30")+labs(x ="Anzahl", title ="Balkendiagramm")
X.tib|>ggplot(aes(x =BS))+geom_bar(aes(y =after_stat(prop), group =1), fill ="steelblue2", color ="gray30")+labs(y ="Anteil", title ="Säulendiagramm")
HinweisAufgabe: Häufigkeiten
Ein Einzelhändler registriert an 20 aufeinander folgenden Tagen die folgende Anzahl an Verkäufen einer Ware.
Tag
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
Anzahl
5
2
3
0
0
1
3
6
0
2
1
0
1
0
2
3
5
1
0
0
Bestimmen Sie ohne Hilfe von R die absoluten und relativen Häufigkeiten, sowie die kumulierten absoluten und kumulierten relativen Häufigkeiten.
Bestätigen Sie nun Ihr Ergebnis mit R.
Erstellen Sie ein Balkendiagramm / Säulendiagramm der Daten.
library(pacman)p_load(tidyverse)x|>tibble()|>ggplot(aes(y =x))+geom_bar(fill ="steelblue2", color ="gray30")+labs(x ="Anzahl")
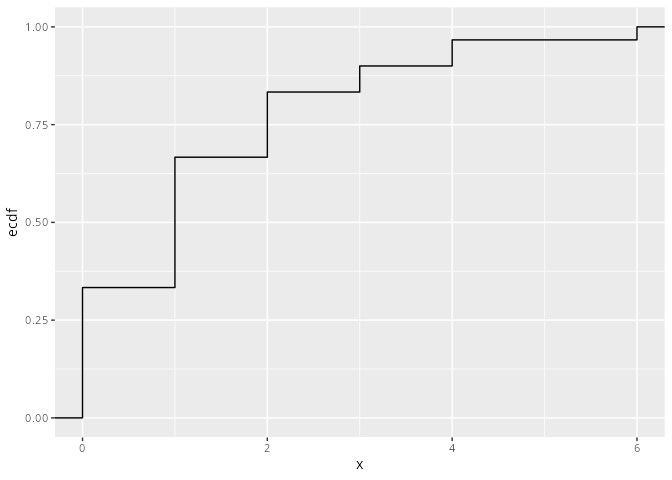
9.2 Empirische Verteilungsfunktion
Für kardinale Merkmale beantwortet die empirische Verteilungsfunktion die Fragestellung:
,,Welcher Anteil der Daten ist kleiner oder gleich einem interessierenden Wert x?’’
WarnungDefinition: Empirische Verteilungsfunktion
Sei X ein kardinales Merkmal mit den sortierten, diskreten Ausprägungen a_i für i \in \{1, \cdots, k\}, d.h. es gilt a_1 < a_2 < \cdots < a_k, dann nennt man die Funktion F: \mathbb{r} \to [0, 1] mit
die empirische Verteilungsfunktion des Merkmals X.
Eigenschaften
Die Funktion F ist damit eine monoton steigende Treppenfunktion, die Werte im Intervall [0, 1] annimmt.
An den Stellen der Ausprägungen a_1, \cdots, a_k springt die Funktion um den entsprechnden Wert der relativen Häufigkeit f_1 = f(a_1), \cdots, f_k = f(a_k) nach oben.
Die Funktion F ist identisch 0 für alle x < a_1, und
identisch 1 für alle x \ge a_k.
Beispiel
Ein Arzt hat im September die folgende Anzahl an Hausbesuchen pro Tag abgestattet.
Tag
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Hausbesuche
0
0
2
3
2
4
0
0
0
1
1
6
0
2
0
Tag
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
Hausbesuche
0
1
1
2
1
4
1
1
0
1
1
0
2
1
3
Daraus ergeben sich die folgenden Häufigkeiten:
Ausprägung (sortiert)
a_j
0
1
2
3
4
6
\sum
absolut
h(a_j)
10
10
5
2
2
1
30
kumuliert absolut
H(a_j)
10
20
25
27
29
30
relativ
f(a_j)
\frac{10}{30}
\frac{10}{30}
\frac{5}{30}
\frac{2}{30}
\frac{2}{30}
\frac{1}{30}
1
kumuliert relativ
F(a_j)
\frac{10}{30}
\frac{20}{30}
\frac{25}{30}
\frac{27}{30}
\frac{29}{30}
1
Mit Hilfe der kumuliert relativen Häufigkeiten kann man nun die empirische Verteilungsfunktion aufstellen. Es ergibt sich
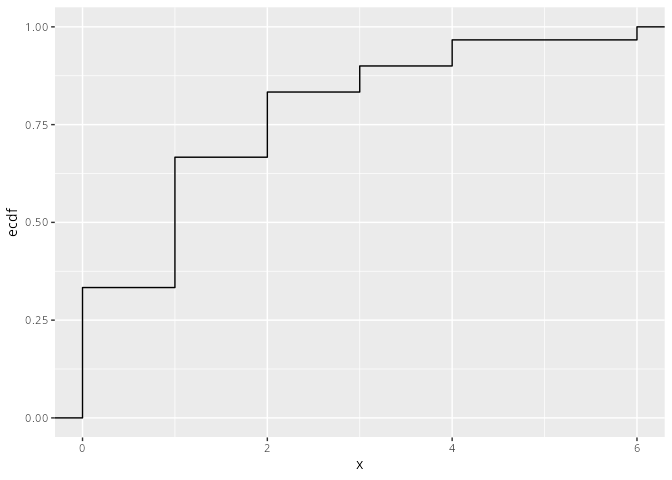
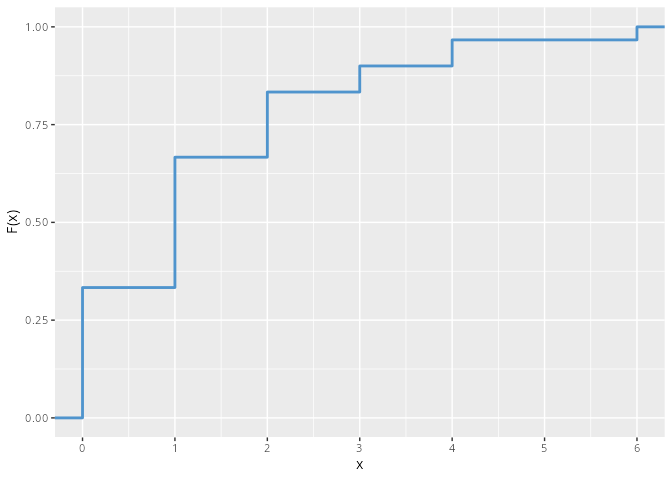
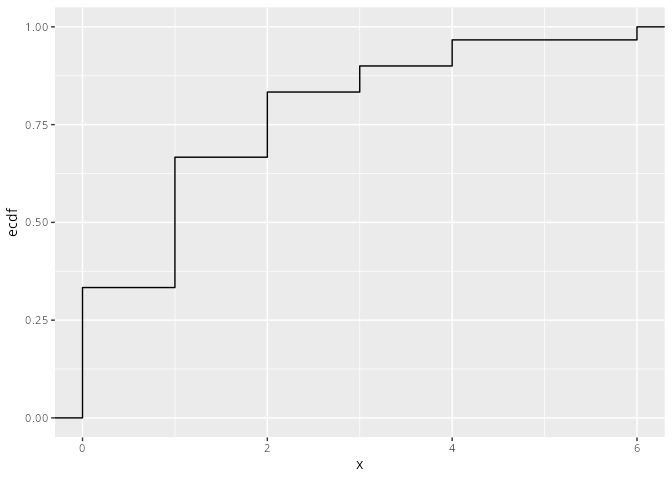
Man sieht, dass sich die Verteilungsfunktion immer an den Stellen der Ausprägungen ändert (springt). Im obigen Beispiel sind das die Stellen x = 0, x = 1, x = 2, x = 3, x=4 und x=6.
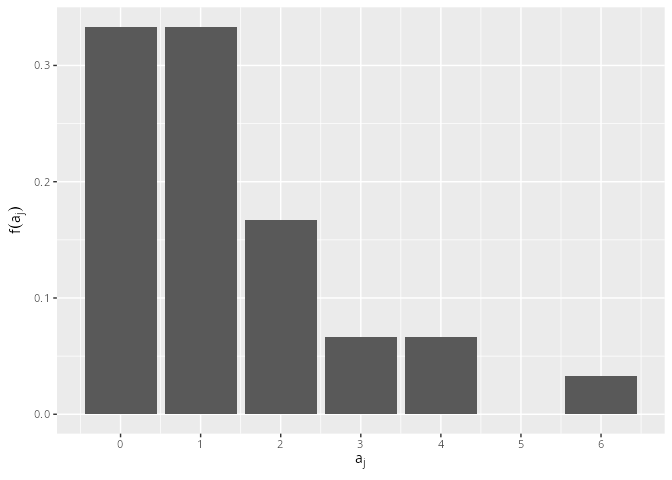
x<-c(0,0,2,3,2,4,0,0,0,1,1,6,0,2,0,0,1,1,2,1,4,1,1,0,1,1,0,2,1,3)x.tib<-tibble(x)x.tib|>ggplot(aes(x =x, y =after_stat(prop)))+geom_bar(fill ="steelblue2", color ="gray30")+labs(y =expression(f(a[j])), x =expression(a[j]))+scale_x_continuous(breaks =0:6, labels =as.character(0:6))
Abbildung 9.3: Säulendiagrammdiagramm der Daten
x.tib|>ggplot(aes(x =x))+stat_ecdf(linewidth =1, color ="steelblue3")+labs(y ="F(x)")+scale_x_continuous(breaks =0:6)
Abbildung 9.4: Die empirische Verteilungsfunktion mit ggplot2
Bemerkungen
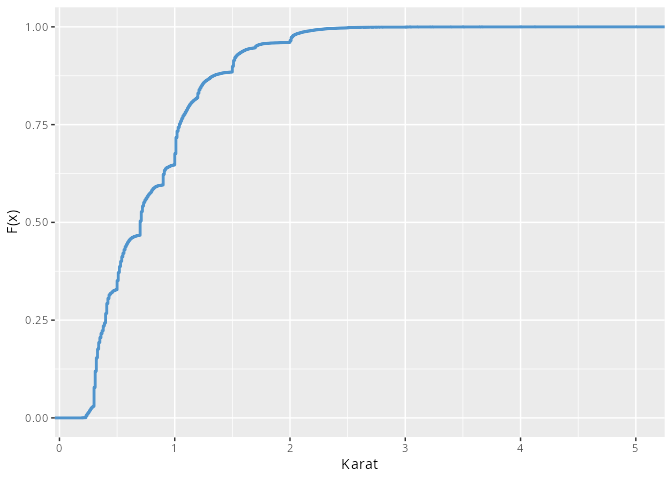
Die empirische Verteilungsfunktion aus dem Paket ggplot2 ist eher für quasi kontinuierliche Daten gemacht, da die Werte mit einer Linie verbunden werden.
diamonds|>filter(between(y, 2, 13))|>ggplot(aes(x =carat))+stat_ecdf(linewidth =1, color ="steelblue3")+labs(y ="F(x)", x ="Karat")
Abbildung 9.5: Die empirische Verteilungsfunktion bei vielen Daten
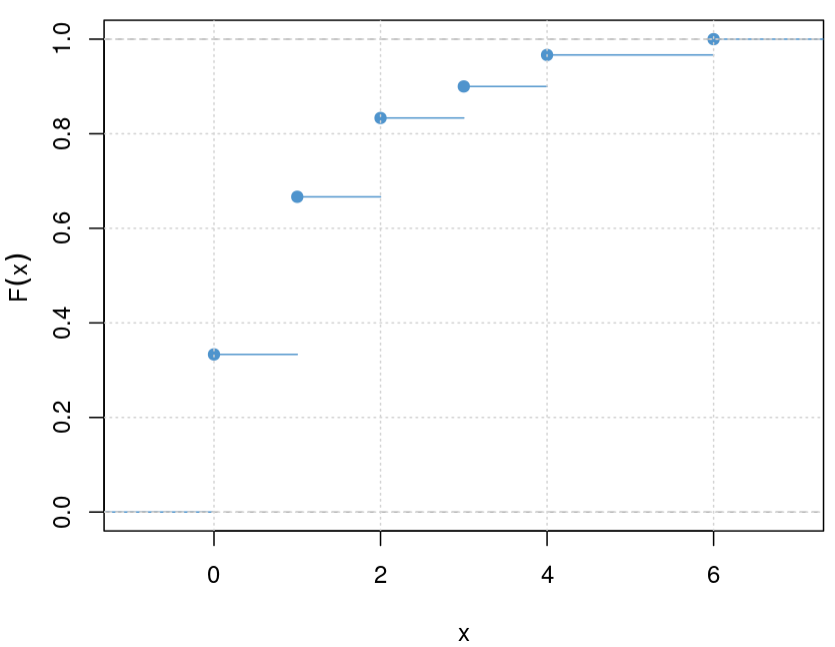
Wenn man wenige Daten hat, so läßt man (anders als in Abbildung 9.4) die vertikalen Linien weg, so dass die obige Grafik so aussieht
Abbildung 9.6: Empirische Verteilungsfunktion bei wenigen Daten.
HinweisAufgabe: Empirische Verteilungsfunktion
Zeichnen Sie für die Verkäufe des Einzelhändler aus Kapitel 9.1 die empirische Verteilungsfunktion: zuerst ohne R und danach zur Kontrolle mit R.
Die empirischen Quantile sind im Wesentlichen eine Umkehrung der empirischen Verteilungsfunktion.
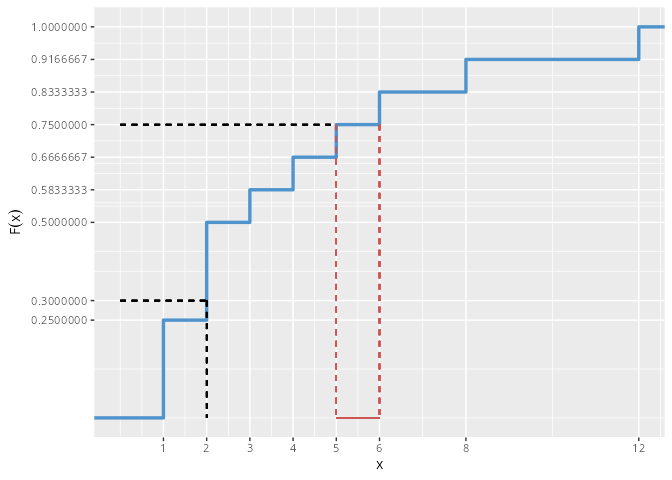
WarnungDefinition: Empirisches Quantil
Jeder Wert \tilde{x}_p mit p \in (0, 1) für den mindestens ein Anteil p der Daten kleiner oder gleich \tilde{x}_p und mindestens ein Anteil 1-p größer oder gleich \tilde{x}_p ist, heißt empirischesp-Quantil.
Damit gilt für das p-Quantil:
\begin{aligned}
\tilde{x}_p = x_{[\lceil n\cdot p \rceil ]} & : \text{falls $n\cdot p \notin \mathbb{N}$} \\
\tilde{x}_p \in \left[x_{[n \cdot p]}, x_{[n \cdot p + 1]} \right) & : \text{falls $n\cdot p \in \mathbb{N}$ }
\end{aligned}
Dabei bezeichnet \lceil n \cdot p \rceil das Aufrunden von n\cdot p auf die nächste ganze Zahl.
Erklärung zur Berechnung
Zuerst multiplizieren n \cdot p, wobei n die Anzahl der Beobachtungen ist. Wir erhalten einen Wert aus dem Intervall [0, n]. Nun gibt es zwei Möglichkeiten:
n \cdot p \notin \mathbb{N}:
n \cdot p ist keine natürliche Zahl, so runden wir die erhaltene Zahl auf die nächste natürliche Zahl auf. Die Schreibweise für diese Operation ist \lceil n \cdot p \rceil.
das gesuchte Quantil ist dann der \lceil n \cdot p \rceil-te Wert aus Rangwertreihe (der sortierten Rohdatenliste). Die Schreibweise hierfür ist x_{[\lceil n \cdot p \rceil]}.
WichtigAchtung
Der aufgerundete Wert \lceil n \cdot p \rceil ist nicht das Quantil, sondern die Position des gesuchten Wertes in der Rangwertreihe!
n \cdot p \in \mathbb{N}:
Ist n \cdot p eine natürliche Zahl, so ist das gesuchte Quantil nicht eindeutig. Jede Zahl im Intervall [x_{[n \cdot p]}, x_{[n \cdot p + 1]}) ist ein zulässiger Wert, wobei x_{[n \cdot p]} der (n \cdot p)-te Wert der Rangwertliste ist und x_{[n \cdot p + 1]} der (n \cdot p + 1)-te Wert der Rangwertliste ist.
Welcher Wert nun aus dem Intervall genommen wird hängt von der verwendeten Methode ab. Welche Methode verwendet wird hängt wiederum von der Anwendung, zum Beispiel der Community in der man publiziert, ab.
Eine einfach zu berechnende (und in dieser Vorlesung vorwiegend verwendete) Methode ist die folgende Wahl:
\begin{aligned}
\tilde{x}_p = \begin{cases} x_{[\lceil n \cdot p\rceil]} & : \text{falls $n\cdot p \notin \mathbb{N}_0$} \\
\frac{1}{2}\left(x_{[n \cdot p]} + x_{[n \cdot p + 1]}\right) & : \text{falls $n\cdot p \in \mathbb{N}_0$}
\end{cases}.
\end{aligned}
Diese Wahl entspricht der Mitte des Intervalls. Sie wird in R durch die Verwendung des Arguments type=2 in der Funktion quantile() realisiert. Geben wir das Argument type= nicht an, so wird der type=7 verwendet. Dies entspricht einer linearen Interpolation zwischen den möglichen Werten. Dieser Typ, sowie type=6, was einer symmetrischen Gewichtung entspricht, wird häufig in wirtschaftspsychologischen Veröffentlichungen verwendet. Sozialwissenschaftler nutzen neben type=6 auch type=4, da durch diese eine geringere Verzerrung bei Ausreißern gewährleistet werden kann und Data Science, Informatik und Machine Learning nutzen im wesentlichen type=7 oder manchmal auch type=5. In der Hilfe ?quantile werden die Berechnungsmethoden der einzelnen Typen erklärt.
Abbildung 9.7: Eingezeichnet sind Quantile zu p = 0.3 und p = 0.75. Man kann erkennen, dass ersteres \tilde{x}_{0.30} = 0.2 eindeutig ist während das zweite Quantil \tilde{x}_{0.75} \in [5, 6] aus einem Intervall gewählt werden kann. Je nach Methode wird ein anderer Wert aus dem Intervall genommen. Bei der R-Funktion quantile() geschieht die Auswahl der Methode mit Hilfe des Arguments type=, wobei insgesamt neun verschiedene Methoden zur Auswahl stehen.
Erklärung
Im obigen Beispiel ist n = 12. Damit ergibt sich zum Beispiel für p = 0.3, dass 0.3 \cdot 12 = 3.6 \notin \mathbb{N} ist. Damit ist das Quantil eindeutig, und man nimmt (wegen \lceil 3.6\rceil = 4) den vierten Wert der sortierten Rohdaten. Es ergibt sich \tilde{x}_{0.3} = 2.
Im Fall p = 0.75 ist allerding 0.75 \cdot 12 = 9 \in \mathbb{N}, das heißt das Quantil ist nicht eindeutig und \tilde{x}_{0.75} \in [5, 6]. In der obigen Wahl (type = 2) wird der neunte und der zehnte Wert der sortierten Rohdaten gemittelt und es ergibt sich \tilde{x}_{0.75} = 5.5.
Selbsttest: Empirische Quantile
Schwierigkeit: ★★☆☆
Gegeben sind zu einem metrischen Merkmal X die Rohdaten
Seien x_1, x_2, \cdots, x_n die Rohdaten mit den Ausprägungen a_1, a_2, \cdots, a_k und den relativen Häufigkeiten f_1 = f(a_1), f_2 = f(a_2), \cdots, f_k = f(a_k). Dann berechnet man das arithmetische Mittel\overline{x} mittels
\overline{x} = \frac{1}{n} \sum_{j=1}^n x_j \quad \text{oder über die relativen Häufigkeiten mittels} \quad \overline{x} = \sum_{j=1}^k a_j f_j.
Beispiel
Für die Rohdaten aus dem obigen Beispiel ergibt sich:
Damit hat der Median die Eigenschaft, dass mindestens 50% der Daten kleiner oder gleich x_{\text{med}} sind und 50% der Daten größer oder gleich x_{\text{med}} sind und entspricht damit dem 50% Quantil.
Man berechne das arithmetische Mittel und den Median der folgenden (bereits sortierten) Rohdaten x1 bzw. x2, zuerst händisch auf einem Blatt Papier und dann mit R:
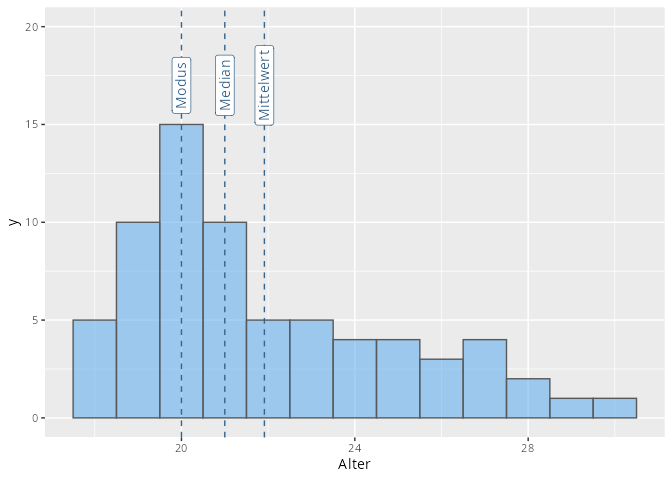
Der Modus (oder auch Modalwert) x_{\text{mod}} ist die Ausprägung mit der größten Häufigkeit. Der Modus ist eindeutig, wenn die Häufigkeitsverteilung ein eindeutiges Maximum besitzt.
Kommen zwei Ausprägungen am Häufigsten vor, so spricht man auch von einer bimodalen Datenreihe, bei mehr als zwei solcher Ausprägungen von multimodal.
Der Modus ist das wichtigste Lagemaß für kategoriale Daten, da er auch für nominale Daten sinnvoll ist.
Für metrische Merkmale ist der Modus ebenfalls sinnvoll, da z.B. das arithmetische Mittel oft mit keiner der möglichen Ausprägungen übereinstimmt (niemand hat beispielsweise 10,3 Bücher.)
Abbildung 9.8: Modus bei kategorialen Daten
Abbildung 9.9: Modus bei metrischen Daten
9.4.4 Quartile
Quartile sind spezielle Quantile, nämlich die bei denen wir die Daten in vier Teile einteilt.
Das erste Quartil Q_1 = \tilde{x}_{0.25} wird so gewählt, dass 25\% der Daten kleiner sind als der Punkt und 75\% der Daten größer als der Punkt.
Das zweite Quartil Q_2= \tilde{x}_{0.50} ist der Median, ist also so gewählt, dass 50\% der Daten kleiner sind als der Punkt.
Das dritte Quartil Q_3= \tilde{x}_{0.75} wird so gewählt, dass 75\% der Daten kleiner sind als der Punkt und 25\% der Daten größer als der Punkt.
Quartile sind beim erstellen von Boxplots wichtig.
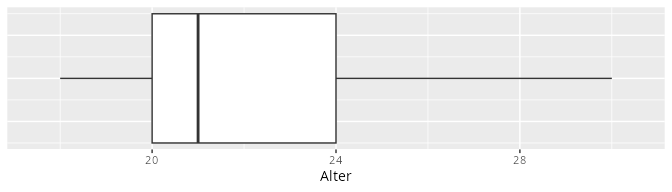
9.5 Boxplots
Boxplots sind kompakte Darstellung eines metrischen Merkmals X bei denen wenige interessante Kenngrößen, nämlich die Quartile, sowie das Minimium und das Maximum der Verteilung, sichtbar gemacht werden. Boxplots sind neben Histogrammen eine sehr gute Wahl um eindimensionale metrische Verteilungen zu visualisieren.
Er ist wie folgt aufgebaut
Die Länge der Box wird bestimmt durch
das 25%-Quantil \tilde{x}_{0.25}. Dies ist die untere Kante der Box,
das 75%-Quantil \tilde{x}_{0.75}. Das ist die obere Kante der Box.
Bemerkung: Die Länge der Box \text{IQR} = \tilde{x}_{0.75}- \tilde{x}_{0.25} nennt man den Interquartilsabstand.
Den Medianx_{\text{med}} = \tilde{x}_{0.50}. Dies ist die Linie (manchmal auch Punkt) innerhalb der Box. Der Median kann auch mit den Rändern der Box zusammenfallen.
Die Whisker sind die Linien die an der Box anfangen. Diese enden (jeweils) immer, (sofern sie existieren) bei dem äußersten Datenpunkt der maximal den 1,5-fachen Interquartilsabstand von der Box hat.
Die Ausreißer sind die Punkte, die außerhalb der Whisker liegen. Existieren keine Ausreißer, so gehen die Whisker bis zum Minimum x_{\text{min}} und bis zum Maximum x_{\text{max}}.
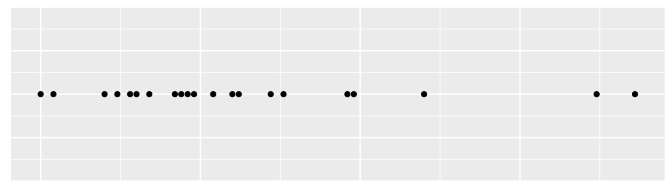
Datenpunkte
Abbildung 9.10: Die Datenpunkte (eindimensionale Darstellung)
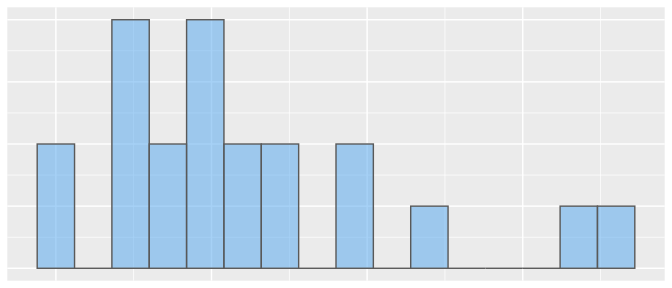
Histogramm
Histogramm der Daten
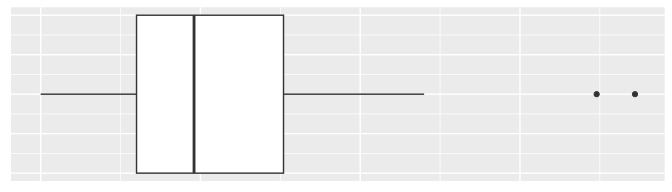
Boxplot
dat.boxplot|>ggplot(aes(x =y))+geom_boxplot(width =0.4)+labs(x =NULL, y =NULL)+theme(axis.text.x=element_blank(), axis.ticks.x=element_blank(), axis.text.y=element_blank(), axis.ticks.y=element_blank())
Abbildung 9.11: Boxplot der Daten.
Bemerkungen
Die Boxplotfunktion geom_boxplot() nutzt andere Methoden um die Quantile und die Whisker zu bestimmen als zum Beispiel die boxplot() Funktion, die type=2-Quantile nutzt. Bei großen Datensätzen spielt das keine Rolle, allerdings macht es bei einer geringen Beobachtungszahl einen sichtbaren Unterschied.
Die Argumente in den Funktionen theme() in den oberen Beispielen sorgen dafür, dass die Achsen (axis.ticks.x= bzw. axis.ticks.y=) und die Beschriftungen der Achsen (axis.text.x= bzw. axis.text.y=) unterdrückt werden.
9.6 Streumaße
Neben den Lagemaßen spielen die Streumaße eine wichtige Rolle bei der Beschreibung von Daten.
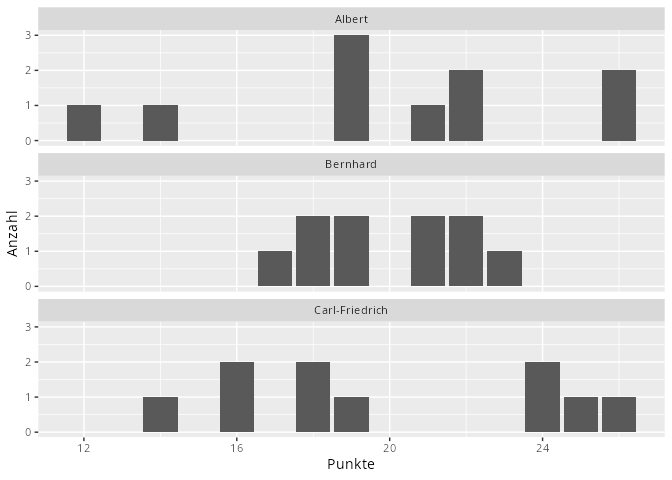
HinweisAufgabe (Vorüberlegung, Gruppe - maximal 10 bis 15 Minuten)
Sie sind Coach eines Basketballteams und wollen einen der folgenden drei Spieler kaufen. In der unten stehenden Tabelle sind ihre Punkte der letzten 10 Spiele aufgelistet. Alle Spieler würden die gleiche Ablösesumme kosten. Für welchen der Spieler würden sie sich entscheiden? Diskutieren Sie in Ihrer Gruppe, einigen Sie sich auf einen Spieler und begründen Sie ihre Entscheidung möglichst mathematisch!
Name
Albert
21
22
19
26
14
19
26
22
12
19
Bernhard
21
19
18
21
23
18
22
19
17
22
Carl-Friedrich
14
24
24
16
18
25
26
18
16
19
Abbildung 9.12: Punkte Basketballspieler
9.6.1 Spannweite
WarnungDefinition: Spannweite
Sei X ein metrisches Merkmal mit n Beobachtungen, dann ist die Spannweite R die Differenz des maximalen Werts und des minimalen Werts der Beobachtungen.
R = x_{[n]} - x_{[1]}
Bemerkungen
Die Bezeichnung R leitet sich aus dem Englischen Range her.
Die Spannweite ist vor allem bei kleinen Datensätzen eine interessante Größe.
Sie ist nicht robust gegenüber Ausreißern, da lediglich der größte und der kleinste Wert in die Berechnung der Spannweite eingeht.
Um die Spannweite mit R zu berechnen kann man die Funktionen max() und min() nutzen
9.6.2 Empirische Varianz und empirische Standardabweichung
WarnungDefinition: Empirische Varianz
Die empirische Varianz (oder mittlere quadratische Abweichung) ist ein Maß für die Streuung einer Datenreihe (x_1, x_2, \cdots, x_n). Sie ist gegeben durch
Die letzte Gleichung ist für Häufigkeitsdaten: a_j sind die Ausprägungen und f_j die relativen Häufigkeiten dieser.
Bemerkung
Die empirische Varianz ist quadratisch in den ‘Einheiten’. Daher gibt man als Streuung meist die (empirische) Standardabweichung\sigma an.
Beispiel
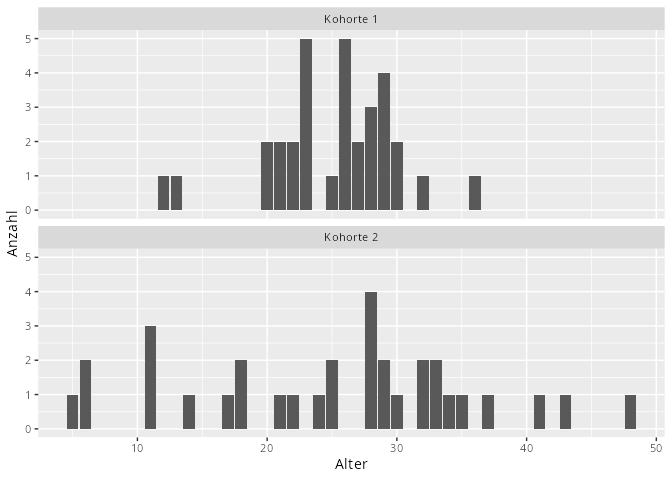
In der folgenden Datentabelle wurden zwei Kohorten mit jeweils 32 Leuten nach Ihrem Alter gefragt, wobei das arithmetische Mittel bei beiden Gruppen in etwa gleich ist.
Datenreihe
\overline{x}
\sigma^2
\sigma
Kohorte 1
25.09
23.65
4.86
Kohorte 2
25.06
117.87
10.86
df|>ggplot(aes(x =Alter))+geom_bar(fill ="steelblue2", color ="gray30")+facet_wrap(~Kohorte, ncol =1)+labs(y ="Anzahl")
Abbildung 9.13: Kohorten mit verschiedenen Varianzen, aber ähnlichen arithmetischen Mittel
Man kann den Unterschied der beiden Verteilungen gut sehen: die zweite Kohorte ist breiter gestreut. Dies macht sich in der empirischen Varianz bzw. Standardabweichung bemerkbar. Daher gibt man nicht nur das arithmetischer mittel, sondern zusätzlich auch immer die empirische Standardabweichung in der Form \overline{x} \pm \sigma_x an.
Für die erste Kohorte würde man das mittlere Alter angeben als 25.09 \pm 4.86 und für die zweite Kohorte 25.06 \pm 10.86.
WarnungSatz: Verschiebungssatz
Für die empirische Varianz gilt der Verschiebungssatz:
Der Verschiebungssatz macht es einfacher die empirische Varianz (oder Standardabweichung) händisch zu berechnen, da nicht alle Differenzen x_i-\overline{x} berechnet werden müssen.
HinweisAufgabe: Verschiebungssatz
Bestimmen Sie auf analoge Weise den Verschiebungssatz für
Gegeben sind die Merkmalswerte oder Zufallsvariablen (x_1, x_2, \cdots, x_n) mit deren empirischer Varianz {\sigma_x}^2. Führt man die affine Transformation der Form
y_i = ax_i + b
mit a, b \in \mathbb{r} und i \in \{1, 2, \cdots, n\} durch, dann gilt für den Mittelwert \overline{y} und die empirische Varianz {\sigma_y}^2
\begin{aligned}
\overline{y} = a \overline{x} + b \qquad \text{und} \qquad {\sigma_y}^2 = a^2 {\sigma_x}^2.
\end{aligned}
Den Beweis kann (und sollte) als Übung durch einfaches Nachrechnen geführt werden (Einsetzen in die Definitionen).
VorsichtBeweis Transformationsregeln
Für das arithmetische Mittel gilt:
\begin{aligned}
\overline{y} & = \frac{1}{n} \sum_{i=1}^{n} y_i \\
& = \frac{1}{n} \sum_{i=1}^{n} (ax_i + b) \\
& = \frac{1}{n} \sum_{i=1}^{n} ax_i + \frac{1}{n} \sum_{i=1}^{n} b \\
& = a \frac{1}{n} \sum_{i=1}^{n} x_i + \frac{1}{n} nb \\
& = a \overline{x} + b
\end{aligned}
In einem amerikanischen Journal lesen Sie über ein Experiment bei dem unter anderem die Raumtemperatur mehrfach gemessen wurde. Diese betrug \overline{T} = 73.2^{\circ}F bei einer Standardabweichung von \sigma_{T} = 0.9^{\circ}F. Welchen Werten entspricht dies in Grad Celsius?
VorsichtAntwort
Zuerst muss man wissen, wie Grad Fahrenheit (Variable x) in Grad Celsius (Variable y) transformiert:
\begin{aligned}
y = \frac{5}{9} x - \frac{160}{9}
\end{aligned}
Damit ergibt sich für die Temperatur etwa (20.9 \pm 0.5)^\circ C.
9.6.3 Empirische Varianz und Standardabweichung in R
In R gibt es keine implementierte Funktion für die empirische Varianz oder die empirische Standardabweichung. Allerdings sind die (schätzertreuen) Funktionen var(), die Stichproben-Varianz und sd(), die Stichproben-Standardabweichung implementiert. Beide Funktionen werden in der induktiven Statistik benötigt, und sind gegeben durch
für die Varianz s^2. Die Standardabweichung s ist die Wurzel aus der Varianz. Der Unterschied liegt also im Vorfaktor. Wir wollen für die empirische Varianz nun selbst eine Funktion schreiben, die wir dann bei Bedarf nutzen können.
# Funktion für die empirische Varianz:evar<-function(x, na.rm=FALSE){rval<-mean((x-mean(x, na.rm =na.rm))^2, na.rm =na.rm)return(rval)}
Erklärung
Die Funktion evar() hat zwei Argumente:
Das erste ist x= ein numerischer Vektor für den die empirische Varianz berechnet werden soll.
Das zweite Argument ist na.rm= in dem angegeben werden soll, wie mit fehlenden Werten (NAs) umgegangen werden soll. dies wird komplett analog zu dem Argument na.rm= in sum(), median() und vor allem mean() sein.
Innerhalb der Funktion wird vom Vektor x der Mittelwert abgezogen und quadriert. Mit der äußeren Funktion mean() wird über diese gemittelt, was das Gleiche ist wie diese so entstehende Werte zu summieren und durch die Anzahl zu teilen.
Das Argument na.rm= der neuen Funktion wird beiden Funktion mean() übergeben. Das beudeutet, dass in den Ausdrücken na.rm=na.rm die linke Seite das Argument der Funktion mean() ist, die rechte Seite aber der Wert des Arguments aus der Funktion evar(). Dies ist beim ersten Lesen vielleicht ein wenig verwirrend, aber sinnvoll, da so gewährleistet ist, dass die Argumentnamen gleich sind, was für den Benutzer sehr angenehm ist.
In der Funktion return() steht der Rückgabewert der Funktion, also das was die Funktion ausgiebt, wenn sie aufgerufen wird. Dies muss ein einzelnes R-Objekt sein. In unserem Fall ist dies die von uns definierte Variable rval (die nur innerhalb der Funktion evar() existiert.
Beispiel
Wir wollen die empirische Varianz und die empirische Standardabweichung der folgenden Vektoren berechnen:
Wir sehen an den Beispielen, dass die Funktion evar() genau das macht, was wir von ihr wollen. Beinhaltet ein Vektor NAs, so können diese mit Hilfe des Arguments na.rm = TRUE herausgenommen, das heißt ignoriert werden.
HinweisAufgabe: Empirische Standardabweichung
Bestimmen Sie die empirische Varianz und die empirische Standardabweichung des Vektors
schriftlich (ohne Taschenrechner). Bestimmen Sie die Standardabweichung auf mehrere Arten (mit und ohne Verschiebungssatz, aus den Rohdaten direkt und über die relativen Häufigkeiten)
Schreiben Sie analog zu oben eine R-Funktion um die empirische Varianz zu berechnen. Allerdings soll (anders als bei der obigen Funktion evar()) der Verschiebungssatz verwendet werden.
Schreiben Sie außerdem eine Funktion esd() für die empirsche Standardabweichung.
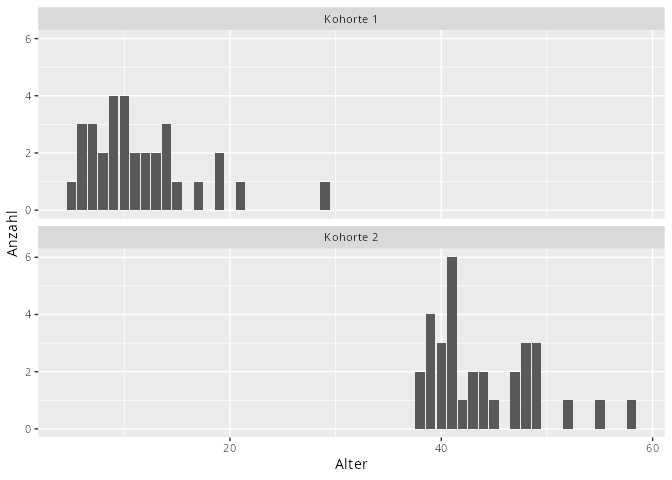
df|>ggplot(aes(x =Alter))+geom_bar(fill ="steelblue2", color ="gray30")+facet_wrap(~Kohorte, ncol =1)+labs(y ="Anzahl")
Abbildung 9.14: Beide Kohorten haben eine ähnliche Varianz, aber verschiedene arithmetische Mittel. Der Variationskoeffizent ist dementsorechend unterschiedlich.
Das Ergebnis der Untersuchung eines kardinalskalierten Merkmals X sei
i
1
2
3
4
5
Ausprägung
1
5
6
10
12
Anzahl
8
5
1
8
13
Bestimmen Sie die folgenden Kenngrößen.
Das arithmetische Mittel ist \overline{x}=
Der Modalwert ist x_{\text{mod}}=
Die mittlere quadratische Abweichung ist \text{MQA}=
Die Spannweite ist \text{R}=
Der Variationskoeffizient ist v=
Der Median ist x_{\text{med}}=
Die Standardabweichung ist \sigma=
Das arithmetische Mittel ist \overline{x}=7.8571
Der Modalwert (oder auch Modus) die Ausprägung, die am häufigsten in den Rohdaten vorkommt: x_{\text{mod}}=12
Die mittlere quadratische Abweichung ist \text{MQA}=19.4367
Die Spannweite ist \text{R}=x_{\text{max}}-x_{\text{min}}=11
Der Variationskoeffizient ist v=\frac{\sigma}{\overline{x}}=0.5611
Der Median ist x_{\text{med}}=10
Die Standardabweichung ist \sigma=4.4087
Das Ergebnis der Untersuchung eines kardinalskalierten Merkmals X sei
i
1
2
3
4
5
6
Ausprägung
2
3
5
6
10
12
Anzahl
9
13
7
8
5
3
Bestimmen Sie die folgenden Kenngrößen.
Der Variationskoeffizient ist v=
Die mittlere quadratische Abweichung ist \text{MQA}=
Der Median ist x_{\text{med}}=
Das arithmetische Mittel ist \overline{x}=
Die Spannweite ist \text{R}=
Die Standardabweichung ist \sigma=
Der Modalwert ist x_{\text{mod}}=
Der Variationskoeffizient ist v=\frac{\sigma}{\overline{x}}=0.6032
Die mittlere quadratische Abweichung ist \text{MQA}=9.1773
Der Median ist x_{\text{med}}=5
Das arithmetische Mittel ist \overline{x}=5.0222
Die Spannweite ist \text{R}=x_{\text{max}}-x_{\text{min}}=10
Die Standardabweichung ist \sigma=3.0294
Der Modalwert (oder auch Modus) die Ausprägung, die am häufigsten in den Rohdaten vorkommt: x_{\text{mod}}=3
Das Ergebnis der Untersuchung eines kardinalskalierten Merkmals X sei
i
1
2
3
4
5
Ausprägung
300
700
800
1000
1100
Anzahl
2
13
11
9
5
Bestimmen Sie die folgenden Kenngrößen.
Die mittlere quadratische Abweichung ist \text{MQA}=
Das arithmetische Mittel ist \overline{x}=
Der Variationskoeffizient ist v=
Der Median ist x_{\text{med}}=
Die Spannweite ist \text{R}=
Die Standardabweichung ist \sigma=
Der Modalwert ist x_{\text{mod}}=
Die mittlere quadratische Abweichung ist \text{MQA}=35375
Das arithmetische Mittel ist \overline{x}=825
Der Variationskoeffizient ist v=\frac{\sigma}{\overline{x}}=0.228
Der Median ist x_{\text{med}}=800
Die Spannweite ist \text{R}=x_{\text{max}}-x_{\text{min}}=800
Die Standardabweichung ist \sigma=188.0824
Der Modalwert (oder auch Modus) die Ausprägung, die am häufigsten in den Rohdaten vorkommt: x_{\text{mod}}=700
Das Ergebnis der Untersuchung eines kardinalskalierten Merkmals X sei
i
1
2
3
4
5
Ausprägung
0
60
70
90
120
Anzahl
12
10
10
10
8
Bestimmen Sie die folgenden Kenngrößen.
Der Median ist x_{\text{med}}=
Das arithmetische Mittel ist \overline{x}=
Die Standardabweichung ist \sigma=
Der Variationskoeffizient ist v=
Die mittlere quadratische Abweichung ist \text{MQA}=
Die Spannweite ist \text{R}=
Der Modalwert ist x_{\text{mod}}=
Der Median ist x_{\text{med}}=70
Das arithmetische Mittel ist \overline{x}=63.2
Die Standardabweichung ist \sigma=40.3703
Der Variationskoeffizient ist v=\frac{\sigma}{\overline{x}}=0.6388
Die mittlere quadratische Abweichung ist \text{MQA}=1629.76
Die Spannweite ist \text{R}=x_{\text{max}}-x_{\text{min}}=120
Der Modalwert (oder auch Modus) die Ausprägung, die am häufigsten in den Rohdaten vorkommt: x_{\text{mod}}=0
Das Ergebnis der Untersuchung eines kardinalskalierten Merkmals X sei
i
1
2
3
4
5
6
7
Ausprägung
0
2
4
5
8
9
10
Anzahl
12
7
1
9
4
6
1
Bestimmen Sie die folgenden Kenngrößen.
Das arithmetische Mittel ist \overline{x}=
Die mittlere quadratische Abweichung ist \text{MQA}=
Der Variationskoeffizient ist v=
Der Median ist x_{\text{med}}=
Der Modalwert ist x_{\text{mod}}=
Die Spannweite ist \text{R}=
Die Standardabweichung ist \sigma=
Das arithmetische Mittel ist \overline{x}=3.975
Die mittlere quadratische Abweichung ist \text{MQA}=11.9744
Der Variationskoeffizient ist v=\frac{\sigma}{\overline{x}}=0.8705
Der Median ist x_{\text{med}}=4.5
Der Modalwert (oder auch Modus) die Ausprägung, die am häufigsten in den Rohdaten vorkommt: x_{\text{mod}}=0
Die Spannweite ist \text{R}=x_{\text{max}}-x_{\text{min}}=10
Die Standardabweichung ist \sigma=3.4604
Das Ergebnis der Untersuchung eines kardinalskalierten Merkmals X sei
i
1
2
3
4
5
6
7
Ausprägung
0
20
40
60
70
80
90
Anzahl
3
10
9
3
1
1
8
Bestimmen Sie die folgenden Kenngrößen.
Der Variationskoeffizient ist v=
Der Modalwert ist x_{\text{mod}}=
Der Median ist x_{\text{med}}=
Die Standardabweichung ist \sigma=
Die mittlere quadratische Abweichung ist \text{MQA}=
Das arithmetische Mittel ist \overline{x}=
Die Spannweite ist \text{R}=
Der Variationskoeffizient ist v=\frac{\sigma}{\overline{x}}=0.6495
Der Modalwert (oder auch Modus) die Ausprägung, die am häufigsten in den Rohdaten vorkommt: x_{\text{mod}}=20
Der Median ist x_{\text{med}}=40
Die Standardabweichung ist \sigma=29.8759
Die mittlere quadratische Abweichung ist \text{MQA}=892.5714
Das arithmetische Mittel ist \overline{x}=46
Die Spannweite ist \text{R}=x_{\text{max}}-x_{\text{min}}=90
Das Ergebnis der Untersuchung eines kardinalskalierten Merkmals X sei
i
1
2
3
4
5
6
Ausprägung
10
20
30
40
90
100
Anzahl
6
12
8
8
9
7
Bestimmen Sie die folgenden Kenngrößen.
Der Median ist x_{\text{med}}=
Der Modalwert ist x_{\text{mod}}=
Das arithmetische Mittel ist \overline{x}=
Die Spannweite ist \text{R}=
Der Variationskoeffizient ist v=
Die mittlere quadratische Abweichung ist \text{MQA}=
Die Standardabweichung ist \sigma=
Der Median ist x_{\text{med}}=30
Der Modalwert (oder auch Modus) die Ausprägung, die am häufigsten in den Rohdaten vorkommt: x_{\text{mod}}=20
Das arithmetische Mittel ist \overline{x}=47.4
Die Spannweite ist \text{R}=x_{\text{max}}-x_{\text{min}}=90
Der Variationskoeffizient ist v=\frac{\sigma}{\overline{x}}=0.7058
Die mittlere quadratische Abweichung ist \text{MQA}=1119.24
Die Standardabweichung ist \sigma=33.455
Das Ergebnis der Untersuchung eines kardinalskalierten Merkmals X sei
i
1
2
3
4
5
Ausprägung
0
0.4
0.5
0.7
0.9
Anzahl
2
3
12
5
3
Bestimmen Sie die folgenden Kenngrößen.
Der Median ist x_{\text{med}}=
Das arithmetische Mittel ist \overline{x}=
Der Modalwert ist x_{\text{mod}}=
Die Spannweite ist \text{R}=
Die mittlere quadratische Abweichung ist \text{MQA}=
Der Variationskoeffizient ist v=
Die Standardabweichung ist \sigma=
Der Median ist x_{\text{med}}=0.5
Das arithmetische Mittel ist \overline{x}=0.536
Der Modalwert (oder auch Modus) die Ausprägung, die am häufigsten in den Rohdaten vorkommt: x_{\text{mod}}=0.5
Die Spannweite ist \text{R}=x_{\text{max}}-x_{\text{min}}=0.9
Die mittlere quadratische Abweichung ist \text{MQA}=0.0471
Der Variationskoeffizient ist v=\frac{\sigma}{\overline{x}}=0.4049
Die Standardabweichung ist \sigma=0.217
Das Ergebnis der Untersuchung eines kardinalskalierten Merkmals X sei
i
1
2
3
4
5
6
Ausprägung
0
100
300
400
500
900
Anzahl
4
10
11
13
1
6
Bestimmen Sie die folgenden Kenngrößen.
Die mittlere quadratische Abweichung ist \text{MQA}=
Die Standardabweichung ist \sigma=
Der Modalwert ist x_{\text{mod}}=
Der Variationskoeffizient ist v=
Der Median ist x_{\text{med}}=
Das arithmetische Mittel ist \overline{x}=
Die Spannweite ist \text{R}=
Die mittlere quadratische Abweichung ist \text{MQA}=66883.9506
Die Standardabweichung ist \sigma=258.6193
Der Modalwert (oder auch Modus) die Ausprägung, die am häufigsten in den Rohdaten vorkommt: x_{\text{mod}}=400
Der Variationskoeffizient ist v=\frac{\sigma}{\overline{x}}=0.7557
Der Median ist x_{\text{med}}=300
Das arithmetische Mittel ist \overline{x}=342.2222
Die Spannweite ist \text{R}=x_{\text{max}}-x_{\text{min}}=900
Das Ergebnis der Untersuchung eines kardinalskalierten Merkmals X sei
i
1
2
3
4
5
Ausprägung
0.1
0.2
0.6
0.8
1.2
Anzahl
5
9
6
8
2
Bestimmen Sie die folgenden Kenngrößen.
Die Standardabweichung ist \sigma=
Der Median ist x_{\text{med}}=
Das arithmetische Mittel ist \overline{x}=
Der Modalwert ist x_{\text{mod}}=
Die mittlere quadratische Abweichung ist \text{MQA}=
Die Spannweite ist \text{R}=
Der Variationskoeffizient ist v=
Die Standardabweichung ist \sigma=0.335
Der Median ist x_{\text{med}}=0.6
Das arithmetische Mittel ist \overline{x}=0.49
Der Modalwert (oder auch Modus) die Ausprägung, die am häufigsten in den Rohdaten vorkommt: x_{\text{mod}}=0.2
Die mittlere quadratische Abweichung ist \text{MQA}=0.1122
Die Spannweite ist \text{R}=x_{\text{max}}-x_{\text{min}}=1.1
Der Variationskoeffizient ist v=\frac{\sigma}{\overline{x}}=0.6837
9.7 Asymmetrie
Neben den Lage- und Streuparameter ist die Asymmetrie der Daten interessant. Wir wollen uns zwei Möglichkeiten ansehen die Schiefe einer Verteilung zu bestimmen. Die erste ist eine rechnerische, die analog zu dem arithmetischen Mittel und der empirischen Standardabweichung zu sehen ist. Die zweite Methode ist qualitativer Natur, aber bei gutartigen Verteilungen relativ einfach zu bestimmen, da man nur das arithmetische Mittel, Den Median und den Modus der Daten berechnen muss.
9.7.1 Die empirische Schiefe
WarnungDefinition: Empirische Schiefe
Die empirische Schiefe ist definiert als
g = \frac{1}{n} \sum_{i=1}^{n} \left(\frac{x_i - \overline{x}}{\sigma}\right)^3
Interpretation der Schiefe
Die empirische Schiefe g kann jeden reellen Wert annehmen.
Ist g > 0, so nennt man die Daten rechtsschief oder linkssteil verteilt. Dies ist insbesondere dann der Fall, wenn die rechte Seite der Verteilung flacher abfällt als die linke.
Ist g \approx 0, so nennt man die Daten symmetrisch verteilt.
ist g < 0 nennt man die Daten linksschief oder rechtssteil verteilt. Dies ist der Fall, wenn die linke Seite der Verteilung flacher abfällt als die rechte.
Beispiel 1
Die Verteilung des Einkommens in einer Gesellschaft ist in der Regel eine rechtsschiefe Verteilung. Die Anzahl der Menschen mit einem sehr hohen Einkommen ist niedrig, allerdings tragen diese durch die dritte Potenz sehr hohe Werte zum Wert der Schiefe g bei, so dass diese positiv wird.
9.7.2 Fechner’sche Lageregel
Gegeben eine ,,gutartige’’ Verteilung der Daten. Das heißt die Daten sind monomodal und es sind etwa gleich viele Werte größer bzw. kleiner als der Median. Dann kann man folgende Faustregel formulieren. Die Daten sind
Schaun wir uns die Altersverteilung einer Umfrage an.
Alter
18
19
20
21
22
23
24
25
26
27
28
29
30
Anzahl
5
10
15
10
5
5
4
4
3
4
2
1
1
Abbildung 9.15: Modus, Median und Mittelwert. Für den Fall x_{\text{mod}} < x_{\text{med}} < \overline{x} ist die Funktion rechtsschief bzw. linkssteil.
Abbildung 9.16: Boxplot der gleichen Daten. Wir sehen, dass Median links in der Box liegt und der rechte Whisker lang ist im Vergleich zum linken.
Das Paket e1071 stellt die Funktion skewness() zur Verfügung mit der wir die Schiefe einer Verteilung berechnen können. Das Argument type= gibt an auf welche Art die Schiefe berechnet werden soll. type=1 nutzt die Formel aus der obigen Definition. In unserem Beispiel liegt der Datensatz in einem Tibble namens daten vor, das Merkmal heißt Alter. Damit können wir dann berechnen.
# oder daten|>summarise(Modus =table(Alter)|>which.max()|>names()|>as.numeric(), Median =median(Alter), Mittelwert =mean(Alter), Schiefe =skewness(Alter, type =1),)
# A tibble: 1 × 4
Modus Median Mittelwert Schiefe
<dbl> <int> <dbl> <dbl>
1 20 21 21.9 0.825
Es ergibt sich eine Schiefe von g \approx 0.82 > 0. Die Daten sind damit wie erwartet rechtsschief verteilt.
Bemerkung:
Der Modus muss für die letzte Berechnung eindeutig sein! Sollte der DAtensatz NAs enthalten, so müssen diese vor der Berechnung noch entfernt werden, zum Beispiel mit drop_na(Alter).
In der folgenden Abbildung werden die Verteilungen einer Variable, gegeben durch zwei Stichproben (A und B), mithilfe paralleler Boxplots dargestellt. Welche der folgenden Aussagen sind korrekt? (Hinweis: Die Aussagen sind entweder korrekt oder klar falsch.)
wahr. Beide Verteilungen haben eine ähnliche Lage (z.B. ähnlichen Median).
wahr. Beide Verteilungen haben keine Beobachtungen, die mehr als das 1.5-Fache des Interquartilsabstands über den Boxbereich hinaus liegen.
wahr. Der Interquartilsabstand in Stichprobe A ist deutlich größer als in B.
falsch. Die Schiefe beider Verteilungen ist unterschiedlich. Stichprobe A ist rechtsschief. Stichprobe B ist ungefähr symmetrisch.
falsch. Verteilung B ist ungefähr symmetrisch.
In der folgenden Abbildung werden die Verteilungen einer Variable, gegeben durch zwei Stichproben (A und B), mithilfe paralleler Boxplots dargestellt. Welche der folgenden Aussagen sind korrekt? (Hinweis: Die Aussagen sind entweder korrekt oder klar falsch.)
falsch. Verteilung A hat im Durchschnitt höhere Werte als Verteilung B.
wahr. Beide Verteilungen haben keine Beobachtungen, die mehr als das 1.5-Fache des Interquartilsabstands über den Boxbereich hinaus liegen.
falsch. Der Interquartilsabstand in Stichprobe A ist nicht deutlich größer als in B.
wahr. Die Schiefe beider Verteilungen ist ähnlich; beide sind linksschief.
wahr. Verteilung B ist linksschief.
In der folgenden Abbildung werden die Verteilungen einer Variable, gegeben durch zwei Stichproben (A und B), mithilfe paralleler Boxplots dargestellt. Welche der folgenden Aussagen sind korrekt? (Hinweis: Die Aussagen sind entweder korrekt oder klar falsch.)
falsch. Verteilung B hat im Durchschnitt höhere Werte als Verteilung A.
wahr. Beide Verteilungen haben keine Beobachtungen, die mehr als das 1.5-Fache des Interquartilsabstands über den Boxbereich hinaus liegen.
falsch. Der Interquartilsabstand in Stichprobe A ist nicht deutlich größer als in B.
wahr. Die Schiefe beider Verteilungen ist ähnlich; beide sind ungefähr symmetrisch.
falsch. Verteilung B ist ungefähr symmetrisch.
In der folgenden Abbildung werden die Verteilungen einer Variable, gegeben durch zwei Stichproben (A und B), mithilfe paralleler Boxplots dargestellt. Welche der folgenden Aussagen sind korrekt? (Hinweis: Die Aussagen sind entweder korrekt oder klar falsch.)
wahr. Beide Verteilungen haben eine ähnliche Lage (z.B. ähnlichen Median).
falsch. Es gibt Beobachtungen, die mehr als das 1.5-Fache des Interquartilsabstands über den Boxbereich hinaus liegen (Ausreißer).
wahr. Der Interquartilsabstand in Stichprobe A ist deutlich größer als in B.
wahr. Die Schiefe beider Verteilungen ist ähnlich; beide sind ungefähr symmetrisch.
falsch. Verteilung B ist ungefähr symmetrisch.
In der folgenden Abbildung werden die Verteilungen einer Variable, gegeben durch zwei Stichproben (A und B), mithilfe paralleler Boxplots dargestellt. Welche der folgenden Aussagen sind korrekt? (Hinweis: Die Aussagen sind entweder korrekt oder klar falsch.)
wahr. Beide Verteilungen haben eine ähnliche Lage (z.B. ähnlichen Median).
falsch. Es gibt Beobachtungen, die mehr als das 1.5-Fache des Interquartilsabstands über den Boxbereich hinaus liegen (Ausreißer).
wahr. Der Interquartilsabstand in Stichprobe A ist deutlich größer als in B.
wahr. Die Schiefe beider Verteilungen ist ähnlich; beide sind linksschief.
falsch. Verteilung A ist linksschief.
In der folgenden Abbildung werden die Verteilungen einer Variable, gegeben durch zwei Stichproben (A und B), mithilfe paralleler Boxplots dargestellt. Welche der folgenden Aussagen sind korrekt? (Hinweis: Die Aussagen sind entweder korrekt oder klar falsch.)
falsch. Verteilung A hat im Durchschnitt höhere Werte als Verteilung B.
falsch. Es gibt Beobachtungen, die mehr als das 1.5-Fache des Interquartilsabstands über den Boxbereich hinaus liegen (Ausreißer).
falsch. Der Interquartilsabstand in Stichprobe A ist nicht deutlich größer als in B.
falsch. Die Schiefe beider Verteilungen ist unterschiedlich. Stichprobe A ist linksschief. Stichprobe B ist ungefähr symmetrisch.
wahr. Verteilung B ist ungefähr symmetrisch.
In der folgenden Abbildung werden die Verteilungen einer Variable, gegeben durch zwei Stichproben (A und B), mithilfe paralleler Boxplots dargestellt. Welche der folgenden Aussagen sind korrekt? (Hinweis: Die Aussagen sind entweder korrekt oder klar falsch.)
falsch. Verteilung A hat im Durchschnitt höhere Werte als Verteilung B.
wahr. Beide Verteilungen haben keine Beobachtungen, die mehr als das 1.5-Fache des Interquartilsabstands über den Boxbereich hinaus liegen.
falsch. Der Interquartilsabstand in Stichprobe A ist nicht deutlich größer als in B.
wahr. Die Schiefe beider Verteilungen ist ähnlich; beide sind ungefähr symmetrisch.
wahr. Verteilung B ist ungefähr symmetrisch.
In der folgenden Abbildung werden die Verteilungen einer Variable, gegeben durch zwei Stichproben (A und B), mithilfe paralleler Boxplots dargestellt. Welche der folgenden Aussagen sind korrekt? (Hinweis: Die Aussagen sind entweder korrekt oder klar falsch.)
falsch. Verteilung A hat im Durchschnitt höhere Werte als Verteilung B.
wahr. Beide Verteilungen haben keine Beobachtungen, die mehr als das 1.5-Fache des Interquartilsabstands über den Boxbereich hinaus liegen.
falsch. Der Interquartilsabstand in Stichprobe A ist nicht deutlich größer als in B.
wahr. Die Schiefe beider Verteilungen ist ähnlich; beide sind ungefähr symmetrisch.
falsch. Verteilung A ist ungefähr symmetrisch.
In der folgenden Abbildung werden die Verteilungen einer Variable, gegeben durch zwei Stichproben (A und B), mithilfe paralleler Boxplots dargestellt. Welche der folgenden Aussagen sind korrekt? (Hinweis: Die Aussagen sind entweder korrekt oder klar falsch.)
falsch. Verteilung B hat im Durchschnitt höhere Werte als Verteilung A.
wahr. Beide Verteilungen haben keine Beobachtungen, die mehr als das 1.5-Fache des Interquartilsabstands über den Boxbereich hinaus liegen.
falsch. Der Interquartilsabstand in Stichprobe A ist nicht deutlich größer als in B.
wahr. Die Schiefe beider Verteilungen ist ähnlich; beide sind ungefähr symmetrisch.
falsch. Verteilung A ist ungefähr symmetrisch.
In der folgenden Abbildung werden die Verteilungen einer Variable, gegeben durch zwei Stichproben (A und B), mithilfe paralleler Boxplots dargestellt. Welche der folgenden Aussagen sind korrekt? (Hinweis: Die Aussagen sind entweder korrekt oder klar falsch.)
falsch. Verteilung B hat im Durchschnitt höhere Werte als Verteilung A.
wahr. Beide Verteilungen haben keine Beobachtungen, die mehr als das 1.5-Fache des Interquartilsabstands über den Boxbereich hinaus liegen.
falsch. Der Interquartilsabstand in Stichprobe A ist nicht deutlich größer als in B.
wahr. Die Schiefe beider Verteilungen ist ähnlich; beide sind ungefähr symmetrisch.
falsch. Verteilung A ist ungefähr symmetrisch.
9.8 Klassierte Daten
Bei stetigen und quasi-stetigen Merkmalen ergibt das Auszählen, also die Angabe einer absoluten Häufigkeit der Ausprägungen keinen Sinn.
Um die Daten ggf. besser behandeln zu können bildet man Klassen. Die Idee ist
Eine Gruppierung innerhalb benachbarter Intervalle vorzunemhmen
wobei sich eine Klassenbreite von d_k = c_{k+1} - c_k ergibt.
Nun zählt man die Häufigkeiten (bzw. relativen Häufigkeiten) für jede Klasse.
Für die Visualisierung wählt man ein Histogramm (das sind keine(!) Säulendiagramme). Die Höhe der Kästen wird durch die (relativen) Häufigkeiten bestimmt (siehe Konstruktion).
Nachteil der Klassenbildung ist ein Informationsverlust, und es muss ein geeigneter Kompromiss zwischen Übersichtlichkeit (zu kleine Klassen) und hohem Informationsverlust (zu große Klassen) gefunden werden.
Abbildung 9.17: Zu wenige Klassen
Abbildung 9.18: Zu viele Klassen
Abbildung 9.19: Übersichtliche Anzahl an Klassen bei denen der Informationsverlust überschaubar ist.
9.8.1 Konstruktion eines Histogramms
Ein Histogramm ist die Darstellungsform für klassierte, metrische Daten.
Die Flächen sind proportional zu Häufigkeit, das heißt es gilt:
dabei ist c eine frei wählbare Konstante. Wählt man c = 1, so ist die Fläche gleich der absoluten Häufigkeit. Für c = \frac{1}{n} ist die Fläche die relativen Häufigkeit.
Beispiel
In einer Datentabelle daten sind die Körpergrößen von 200 Profisportlern in Zentimetern klassiert angegeben.
Tabelle 9.1: Körpergrößen von Profisportlern klassiert.
Klasse
[150, 160)
[160, 170)
[170, 175)
[175, 180)
[180, 190)
[190, 210)
j
1
2
3
4
5
6
h(a_j)
8
20
36
58
56
22
Breite_j
10
10
5
5
10
20
Höhe_j
0.0040
0.01000
0.0360
0.0580
0.0280
0.0055
Breite_j\cdot Höhe_j
0.04
0.10
0.18
0.29
0.28
0.11
Da die Klassen verschiedene Breiten haben, bietet es sich an mit c = \frac{1}{n} = \frac{1}{200} die Höhen zu berechnen, da so die Fläche Breite_j\cdot Höhe_j jeder Klasse als prozentualer Anteil aller Beobachtungen zu interpretieren ist. Im Beispiel sind in der Klasse [175, 180) genau 29% aller Beobachtungen (hier: Profisportler).
Möchte man die Daten grafisch, also als Histogramm, darstellen, so geht das zum Beispiel so:
daten|>ggplot(aes(x =Groesse))+geom_histogram(aes(y =after_stat(density)), breaks =c(150, 160, 170, 175, 180, 190, 220), closed ="left", fill ="steelblue2", color ="gray30", alpha =0.5)+# für die Optiklabs(y ="Dichte", x ="Größe")
Das aes-Argument y = after_stat(density) in der geometrischen Funktion geom_histogram() sorgt dafür, dass auf der y-Achse die Dichte abgebildet wird. Das entspricht der Wahl c = \frac{1}{n} bei der Berechnung der Höhe.
Das Argument breaks= gibt die Stellen der Grenzen für das Histogramm an. Dies ist insbesondere dann nötig, wenn die Abstände der Grenzen nicht gleich sind. Bei gleich breiten Klassen kann man mit dem Argument binwidth= die Breite angeben die jede Fläche haben soll oder mit dem Argument bins= die Anzahl aller Rechtecke (Bins).
Da jeder Wert nur zu genau einem Balken gehören darf, muss man an den Grenzen entscheiden zu welcher Seite der Grenzwert geschlagen wird: im obigen Beispiel sind die Intervalle links geschlossen, das heißt die Grenzwerte werden dem rechten Intervall zugeschlagen. Dies muss durch das Argument closed = "left" übergeben werden. Der Standard ist closed = "right", das heißt falls die Intervalle rechts geschlossen sind muss das Argument closed= nicht angegeben werden.
Das Ergebnis der Untersuchung eines kardinalskalierten Merkmals X sei
j
1
2
3
4
5
6
Ausprägung
0.3
0.6
0.9
1.2
1.3
1.4
Anzahl
1
2
6
6
6
4
Es soll ein Histogramm aus den Daten erstellt werden. Bestimmen Sie die Höhen der Balken derart, dass die Summe aller Flächen 1 ist. Geben Sie das Ergebnis auf 4 signifikante Stellen an.
wobei in diesem Fall c = \frac{1}{n} = \frac{1}{25} ist.
Intervall
[0, 0.4 ]
( 0.4, 0.5 ]
( 0.5, 1.3 ]
( 1.3, 1.4]
Breite
0.4
0.1
0.8
0.1
Höhe
0.1
0
1
1.6
Anzahl Beobachtungen
1
0
20
4
Das Ergebnis der Untersuchung eines kardinalskalierten Merkmals X sei
j
1
2
3
4
5
6
Ausprägung
10
20
40
110
130
140
Anzahl
16
8
21
17
18
20
Es soll ein Histogramm aus den Daten erstellt werden. Bestimmen Sie die Höhen der Balken derart, dass die Summe aller Flächen 1 ist. Geben Sie das Ergebnis auf 4 signifikante Stellen an.
wobei in diesem Fall c = \frac{1}{n} = \frac{1}{100} ist.
Intervall
[0, 80 ]
( 80, 110 ]
( 110, 120 ]
( 120, 140]
Breite
80
30
10
20
Höhe
0.005625
0.00566667
0
0.019
Anzahl Beobachtungen
45
17
0
38
Das Ergebnis der Untersuchung eines kardinalskalierten Merkmals X sei
j
1
2
3
4
5
6
Ausprägung
0.1
0.4
0.9
1
1.1
1.2
Anzahl
24
11
7
17
17
24
Es soll ein Histogramm aus den Daten erstellt werden. Bestimmen Sie die Höhen der Balken derart, dass die Summe aller Flächen 1 ist. Geben Sie das Ergebnis auf 4 signifikante Stellen an.
wobei in diesem Fall c = \frac{1}{n} = \frac{1}{100} ist.
Intervall
[0, 0.3 )
[ 0.3, 0.4 )
[ 0.4, 0.7 )
[ 0.7, 1.2]
Breite
0.3
0.1
0.3
0.5
Höhe
0.8
0
0.36666667
1.3
Anzahl Beobachtungen
24
0
11
65
Das Ergebnis der Untersuchung eines kardinalskalierten Merkmals X sei
j
1
2
3
4
5
6
Ausprägung
0
30
50
70
90
110
Anzahl
21
19
21
10
22
7
Es soll ein Histogramm aus den Daten erstellt werden. Bestimmen Sie die Höhen der Balken derart, dass die Summe aller Flächen 1 ist. Geben Sie das Ergebnis auf 4 signifikante Stellen an.
wobei in diesem Fall c = \frac{1}{n} = \frac{1}{100} ist.
Intervall
[0, 30 )
[ 30, 70 )
[ 70, 90 )
[ 90, 110]
Breite
30
40
20
20
Höhe
0.007
0.01
0.005
0.0145
Anzahl Beobachtungen
21
40
10
29
Das Ergebnis der Untersuchung eines kardinalskalierten Merkmals X sei
j
1
2
3
4
5
6
Ausprägung
6
7
9
10
13
14
Anzahl
23
24
24
4
8
17
Es soll ein Histogramm aus den Daten erstellt werden. Bestimmen Sie die Höhen der Balken derart, dass die Summe aller Flächen 1 ist. Geben Sie das Ergebnis auf 4 signifikante Stellen an.
wobei in diesem Fall c = \frac{1}{n} = \frac{1}{100} ist.
Intervall
[0, 8 )
[ 8, 10 )
[ 10, 13 )
[ 13, 14]
Breite
8
2
3
1
Höhe
0.05875
0.12
0.01333333
0.25
Anzahl Beobachtungen
47
24
4
25
Das Ergebnis der Untersuchung eines kardinalskalierten Merkmals X sei
j
1
2
3
4
5
6
Ausprägung
10
20
40
60
130
140
Anzahl
24
1
24
20
10
21
Es soll ein Histogramm aus den Daten erstellt werden. Bestimmen Sie die Höhen der Balken derart, dass die Summe aller Flächen 1 ist. Geben Sie das Ergebnis auf 4 signifikante Stellen an.
wobei in diesem Fall c = \frac{1}{n} = \frac{1}{100} ist.
Intervall
[0, 20 )
[ 20, 60 )
[ 60, 70 )
[ 70, 140]
Breite
20
40
10
70
Höhe
0.012
0.00625
0.02
0.00442857
Anzahl Beobachtungen
24
25
20
31
Das Ergebnis der Untersuchung eines kardinalskalierten Merkmals X sei
j
1
2
3
4
5
6
Ausprägung
0
2
5
6
9
10
Anzahl
5
25
20
21
6
23
Es soll ein Histogramm aus den Daten erstellt werden. Bestimmen Sie die Höhen der Balken derart, dass die Summe aller Flächen 1 ist. Geben Sie das Ergebnis auf 4 signifikante Stellen an.
wobei in diesem Fall c = \frac{1}{n} = \frac{1}{100} ist.
Intervall
[0, 4 ]
( 4, 8 ]
( 8, 9 ]
( 9, 10]
Breite
4
4
1
1
Höhe
0.075
0.1025
0.06
0.23
Anzahl Beobachtungen
30
41
6
23
Das Ergebnis der Untersuchung eines kardinalskalierten Merkmals X sei
j
1
2
3
4
5
6
Ausprägung
0.2
0.3
0.4
0.5
0.8
1.4
Anzahl
1
4
5
23
9
8
Es soll ein Histogramm aus den Daten erstellt werden. Bestimmen Sie die Höhen der Balken derart, dass die Summe aller Flächen 1 ist. Geben Sie das Ergebnis auf 4 signifikante Stellen an.
wobei in diesem Fall c = \frac{1}{n} = \frac{1}{50} ist.
Intervall
[0, 0.4 ]
( 0.4, 1 ]
( 1, 1.2 ]
( 1.2, 1.4]
Breite
0.4
0.6
0.2
0.2
Höhe
0.5
1.06666667
0
0.8
Anzahl Beobachtungen
10
32
0
8
Das Ergebnis der Untersuchung eines kardinalskalierten Merkmals X sei
j
1
2
3
4
5
6
Ausprägung
2
4
6
11
12
13
Anzahl
17
23
17
19
23
1
Es soll ein Histogramm aus den Daten erstellt werden. Bestimmen Sie die Höhen der Balken derart, dass die Summe aller Flächen 1 ist. Geben Sie das Ergebnis auf 4 signifikante Stellen an.
wobei in diesem Fall c = \frac{1}{n} = \frac{1}{100} ist.
Intervall
[0, 5 )
[ 5, 9 )
[ 9, 12 )
[ 12, 13]
Breite
5
4
3
1
Höhe
0.08
0.0425
0.06333333
0.24
Anzahl Beobachtungen
40
17
19
24
Das Ergebnis der Untersuchung eines kardinalskalierten Merkmals X sei
j
1
2
3
4
5
6
Ausprägung
0
0.1
0.4
0.5
0.6
0.9
Anzahl
13
21
14
22
24
6
Es soll ein Histogramm aus den Daten erstellt werden. Bestimmen Sie die Höhen der Balken derart, dass die Summe aller Flächen 1 ist. Geben Sie das Ergebnis auf 4 signifikante Stellen an.
wobei in diesem Fall c = \frac{1}{n} = \frac{1}{100} ist.
Intervall
[0, 0.1 ]
( 0.1, 0.4 ]
( 0.4, 0.8 ]
( 0.8, 0.9]
Breite
0.1
0.3
0.4
0.1
Höhe
3.4
0.46666667
1.15
0.6
Anzahl Beobachtungen
34
14
46
6
9.8.2 Lage- und Streumaße bei klassierten Daten
Auch bei klassierten Daten können Lage- und Streumaße angegeben werden, allerdings nur noch als Näherung, da durch das Klassieren Informationen verloren gegangen sind.
Modus
Die Klasse(n) mit den größten Beobachtungszahl, die Mitte der Klassen sind die Modi. Man bezeichnet diese Klasse auch als Modalklasse. Der wahre Modus muss allerdings nicht einmal in der Modalklasse liegen, und der so berechnete Modus ist ggf.auch kein Beobachtungswert!
Median
Wir bestimmen die Klasse [c_{i-1}, c_i) in der der Median liegt. Nun gibt es mehrere Methoden was wir machen können
Für den Klassen-Median nehmen wir an, dass die Beobachtungen innerhalb der Klasse gleich verteilt sind. Damit bestimmen wir den Median zu:
dabei sind m_i mit i = 1, \cdots, k jeweils die Klassenmitten.
HinweisAufgabe: Lage- und Streuparameter, Histogramm
Das Ergebnis der Untersuchung eines kardinalskalierten Merkmals X sei
i
1
2
3
4
5
Ausprägung
3
4
6
7
9
Anzahl
4
4
6
4
2
Bestimmen Sie das arithmetische Mittel, den Modus, den Median und die Spannweite.
Berechnen Sie die mittlere quadratische Abweichung, die Standardabweichung sowie den Variationskoeffizienten.
Obige Daten werden nun mittels der Intervalle [3, 5), [5, 8) und [8, 12] klassiert. Bestimmen Sie die Rechteckhöhen des Histogramms und zeichnen Sie das Histogramm mit der Hand und dann mit R.
Tipp: Nehmen Sie die Funktion hist() und achten Sie auf die Ränder der Intervalle!
hist(daten, breaks =c(3,5,8,12)# Grenzes der Balken)
Aufgaben zum Kapitel
Schwierigkeit: ★★☆☆
Der Baumarkt IBO hat in Deutschland insgesamt 69 Filialen, die im wesentlichen alle das gleiche Sortiment haben. Die Verkaufszahlen der Produkte variieren in den einzelnen Filialen mitunter stark, so wurde das Produkt Axt Axel in den verschiedenen Filialen zwischen 0 und 10 mal verkauft. Das folgende Säulendiagramm zeigt die Häufigkeiten, also wie viele Filialen das Produkt wie oft verkauft haben.
Bestimmen Sie die folgende Größen. Geben Sie das Ergebnis gerundet auf mindestens zwei(!) Nachkommastellen an. Bestimmen Sie die Lösungen händisch mit einem Taschnrechner
H(5.7) =
F(9.5) =
Der Variationskoeffizient ist v=
Die Standardabweichung ist \sigma=
Die mittlere quadratische Abweichung ist \text{MQA}=
f(7) =
Der Median ist x_{\text{med}}=
Das arithmetische Mittel ist \overline{x}=
H(5.7) =38
F(9.5) =0.97
Der Variationskoeffizient ist v=0.92
Die Standardabweichung ist \sigma=3.61
Die mittlere quadratische Abweichung ist \text{MQA}=13.04
f(7) =0.14
Der Median ist x_{\text{med}}=5
Das arithmetische Mittel ist \overline{x}=3.94
Schwierigkeit: ★★☆☆
Der Baumarkt IBO hat in Deutschland insgesamt 20 Filialen, die im wesentlichen alle das gleiche Sortiment haben. Die Verkaufszahlen der Produkte variieren in den einzelnen Filialen mitunter stark, so wurde das Produkt Walze Waldemar in den verschiedenen Filialen zwischen 0 und 10 mal verkauft. Das folgende Säulendiagramm zeigt die Häufigkeiten, also wie viele Filialen das Produkt wie oft verkauft haben.
Bestimmen Sie die folgende Größen. Geben Sie das Ergebnis gerundet auf mindestens zwei(!) Nachkommastellen an. Bestimmen Sie die Lösungen händisch mit einem Taschnrechner
Das arithmetische Mittel ist \overline{x}=
F(10.2) =
Die mittlere quadratische Abweichung ist \text{MQA}=
H(8.9) =
Der Median ist x_{\text{med}}=
Der Variationskoeffizient ist v=
f(6) =
Die Standardabweichung ist \sigma=
Das arithmetische Mittel ist \overline{x}=2.75
F(10.2) =1
Die mittlere quadratische Abweichung ist \text{MQA}=13.387
H(8.9) =16
Der Median ist x_{\text{med}}=0
Der Variationskoeffizient ist v=1.33
f(6) =0.05
Die Standardabweichung ist \sigma=3.66
Schwierigkeit: ★★☆☆
Der Baumarkt IBO hat in Deutschland insgesamt 25 Filialen, die im wesentlichen alle das gleiche Sortiment haben. Die Verkaufszahlen der Produkte variieren in den einzelnen Filialen mitunter stark, so wurde das Produkt Hobel Horst in den verschiedenen Filialen zwischen 0 und 10 mal verkauft. Das folgende Säulendiagramm zeigt die Häufigkeiten, also wie viele Filialen das Produkt wie oft verkauft haben.
Bestimmen Sie die folgende Größen. Geben Sie das Ergebnis gerundet auf mindestens zwei(!) Nachkommastellen an. Bestimmen Sie die Lösungen händisch mit einem Taschnrechner
Der Variationskoeffizient ist v=
Die mittlere quadratische Abweichung ist \text{MQA}=
f(3) =
Die Standardabweichung ist \sigma=
Der Median ist x_{\text{med}}=
H(3.9) =
Das arithmetische Mittel ist \overline{x}=
F(9.8) =
Der Variationskoeffizient ist v=1.07
Die mittlere quadratische Abweichung ist \text{MQA}=6.218
f(3) =0.12
Die Standardabweichung ist \sigma=2.49
Der Median ist x_{\text{med}}=2
H(3.9) =18
Das arithmetische Mittel ist \overline{x}=2.32
F(9.8) =0.96
Schwierigkeit: ★★☆☆
Der Baumarkt IBO hat in Deutschland insgesamt 77 Filialen, die im wesentlichen alle das gleiche Sortiment haben. Die Verkaufszahlen der Produkte variieren in den einzelnen Filialen mitunter stark, so wurde das Produkt Leiter Ludwig in den verschiedenen Filialen zwischen 0 und 10 mal verkauft. Das folgende Säulendiagramm zeigt die Häufigkeiten, also wie viele Filialen das Produkt wie oft verkauft haben.
Bestimmen Sie die folgende Größen. Geben Sie das Ergebnis gerundet auf mindestens zwei(!) Nachkommastellen an. Bestimmen Sie ihre Lösungen mit R.
H(5.8) =
Das arithmetische Mittel ist \overline{x}=
Der Median ist x_{\text{med}}=
Die mittlere quadratische Abweichung ist \text{MQA}=
Der Variationskoeffizient ist v=
f(10) =
F(4.1) =
Die Standardabweichung ist \sigma=
H(5.8) =47
Das arithmetische Mittel ist \overline{x}=4.48
Der Median ist x_{\text{med}}=4
Die mittlere quadratische Abweichung ist \text{MQA}=12.821
Der Variationskoeffizient ist v=0.8
f(10) =0.08
F(4.1) =0.51
Die Standardabweichung ist \sigma=3.58
Schwierigkeit: ★★☆☆
Der Baumarkt IBO hat in Deutschland insgesamt 34 Filialen, die im wesentlichen alle das gleiche Sortiment haben. Die Verkaufszahlen der Produkte variieren in den einzelnen Filialen mitunter stark, so wurde das Produkt Werkbank Willi in den verschiedenen Filialen zwischen 0 und 10 mal verkauft. Das folgende Säulendiagramm zeigt die Häufigkeiten, also wie viele Filialen das Produkt wie oft verkauft haben.
Bestimmen Sie die folgende Größen. Geben Sie das Ergebnis gerundet auf mindestens zwei(!) Nachkommastellen an. Bestimmen Sie die Lösungen händisch mit einem Taschnrechner
Das arithmetische Mittel ist \overline{x}=
F(5.5) =
f(4) =
Die Standardabweichung ist \sigma=
Die mittlere quadratische Abweichung ist \text{MQA}=
H(6.2) =
Der Variationskoeffizient ist v=
Der Median ist x_{\text{med}}=
Das arithmetische Mittel ist \overline{x}=4.06
F(5.5) =0.62
f(4) =0.15
Die Standardabweichung ist \sigma=3.46
Die mittlere quadratische Abweichung ist \text{MQA}=11.938
H(6.2) =23
Der Variationskoeffizient ist v=0.85
Der Median ist x_{\text{med}}=4
Schwierigkeit: ★★☆☆
Der Baumarkt IBO hat in Deutschland insgesamt 63 Filialen, die im wesentlichen alle das gleiche Sortiment haben. Die Verkaufszahlen der Produkte variieren in den einzelnen Filialen mitunter stark, so wurde das Produkt Walze Waldemar in den verschiedenen Filialen zwischen 0 und 10 mal verkauft. Das folgende Säulendiagramm zeigt die Häufigkeiten, also wie viele Filialen das Produkt wie oft verkauft haben.
Bestimmen Sie die folgende Größen. Geben Sie das Ergebnis gerundet auf mindestens zwei(!) Nachkommastellen an. Bestimmen Sie ihre Lösungen mit R.
H(8.3) =
f(7) =
F(7.4) =
Die mittlere quadratische Abweichung ist \text{MQA}=
Der Variationskoeffizient ist v=
Der Median ist x_{\text{med}}=
Das arithmetische Mittel ist \overline{x}=
Die Standardabweichung ist \sigma=
H(8.3) =48
f(7) =0
F(7.4) =0.67
Die mittlere quadratische Abweichung ist \text{MQA}=15.642
Der Variationskoeffizient ist v=1.05
Der Median ist x_{\text{med}}=2
Das arithmetische Mittel ist \overline{x}=3.76
Die Standardabweichung ist \sigma=3.95
Schwierigkeit: ★★☆☆
Der Baumarkt IBO hat in Deutschland insgesamt 54 Filialen, die im wesentlichen alle das gleiche Sortiment haben. Die Verkaufszahlen der Produkte variieren in den einzelnen Filialen mitunter stark, so wurde das Produkt Säge Serge in den verschiedenen Filialen zwischen 0 und 10 mal verkauft. Das folgende Säulendiagramm zeigt die Häufigkeiten, also wie viele Filialen das Produkt wie oft verkauft haben.
Bestimmen Sie die folgende Größen. Geben Sie das Ergebnis gerundet auf mindestens zwei(!) Nachkommastellen an. Bestimmen Sie ihre Lösungen mit R.
H(1.1) =
Die mittlere quadratische Abweichung ist \text{MQA}=
F(6.9) =
Das arithmetische Mittel ist \overline{x}=
Die Standardabweichung ist \sigma=
Der Median ist x_{\text{med}}=
Der Variationskoeffizient ist v=
f(6) =
H(1.1) =19
Die mittlere quadratische Abweichung ist \text{MQA}=9.731
F(6.9) =0.83
Das arithmetische Mittel ist \overline{x}=3.83
Die Standardabweichung ist \sigma=3.12
Der Median ist x_{\text{med}}=4
Der Variationskoeffizient ist v=0.81
f(6) =0.15
Schwierigkeit: ★★☆☆
Der Baumarkt IBO hat in Deutschland insgesamt 80 Filialen, die im wesentlichen alle das gleiche Sortiment haben. Die Verkaufszahlen der Produkte variieren in den einzelnen Filialen mitunter stark, so wurde das Produkt Spiegel Sputnik in den verschiedenen Filialen zwischen 0 und 10 mal verkauft. Das folgende Säulendiagramm zeigt die Häufigkeiten, also wie viele Filialen das Produkt wie oft verkauft haben.
Bestimmen Sie die folgende Größen. Geben Sie das Ergebnis gerundet auf mindestens zwei(!) Nachkommastellen an. Bestimmen Sie ihre Lösungen mit R.
Der Median ist x_{\text{med}}=
H(7.4) =
Das arithmetische Mittel ist \overline{x}=
f(8) =
Die mittlere quadratische Abweichung ist \text{MQA}=
Die Standardabweichung ist \sigma=
Der Variationskoeffizient ist v=
F(9.9) =
Der Median ist x_{\text{med}}=4
H(7.4) =67
Das arithmetische Mittel ist \overline{x}=4.39
f(8) =0.01
Die mittlere quadratische Abweichung ist \text{MQA}=11.237
Die Standardabweichung ist \sigma=3.35
Der Variationskoeffizient ist v=0.76
F(9.9) =0.94
Schwierigkeit: ★★☆☆
Der Baumarkt IBO hat in Deutschland insgesamt 32 Filialen, die im wesentlichen alle das gleiche Sortiment haben. Die Verkaufszahlen der Produkte variieren in den einzelnen Filialen mitunter stark, so wurde das Produkt Walze Waldemar in den verschiedenen Filialen zwischen 0 und 9 mal verkauft. Das folgende Säulendiagramm zeigt die Häufigkeiten, also wie viele Filialen das Produkt wie oft verkauft haben.
Bestimmen Sie die folgende Größen. Geben Sie das Ergebnis gerundet auf mindestens zwei(!) Nachkommastellen an. Bestimmen Sie ihre Lösungen mit R.
Die Standardabweichung ist \sigma=
Das arithmetische Mittel ist \overline{x}=
f(3) =
F(1.9) =
H(3.8) =
Die mittlere quadratische Abweichung ist \text{MQA}=
Der Variationskoeffizient ist v=
Der Median ist x_{\text{med}}=
Die Standardabweichung ist \sigma=3.45
Das arithmetische Mittel ist \overline{x}=4.16
f(3) =0.06
F(1.9) =0.31
H(3.8) =15
Die mittlere quadratische Abweichung ist \text{MQA}=11.882
Der Variationskoeffizient ist v=0.83
Der Median ist x_{\text{med}}=4
Schwierigkeit: ★★☆☆
Der Baumarkt IBO hat in Deutschland insgesamt 23 Filialen, die im wesentlichen alle das gleiche Sortiment haben. Die Verkaufszahlen der Produkte variieren in den einzelnen Filialen mitunter stark, so wurde das Produkt Säge Serge in den verschiedenen Filialen zwischen 0 und 10 mal verkauft. Das folgende Säulendiagramm zeigt die Häufigkeiten, also wie viele Filialen das Produkt wie oft verkauft haben.
Bestimmen Sie die folgende Größen. Geben Sie das Ergebnis gerundet auf mindestens zwei(!) Nachkommastellen an. Bestimmen Sie die Lösungen händisch mit einem Taschnrechner
f(8) =
F(4.8) =
Das arithmetische Mittel ist \overline{x}=
Die Standardabweichung ist \sigma=
Die mittlere quadratische Abweichung ist \text{MQA}=
H(2.1) =
Der Variationskoeffizient ist v=
Der Median ist x_{\text{med}}=
f(8) =0.17
F(4.8) =0.39
Das arithmetische Mittel ist \overline{x}=5.09
Die Standardabweichung ist \sigma=3.34
Die mittlere quadratische Abweichung ist \text{MQA}=11.123
H(2.1) =6
Der Variationskoeffizient ist v=0.66
Der Median ist x_{\text{med}}=6
Gegeben ist die empirische Verteilungsfunktion F(x) von 50 Beobachtungen im folgenden Diagramm.
h(0)=
H(-19)=
f(50)=
F(-41)=
Der Median x_\text{med}=
Die Spannweite R=
Das arithmetische Mittel \overline{x}=
h(0)= 8
H(-19)= 23
f(50)= 0.2
F(-41)= 0.28
Der Median x_\text{med}= 0
Die Spannweite R= 350
Das arithmetische Mittel \overline{x}= -23.4
Gegeben ist die empirische Verteilungsfunktion F(x) von 20 Beobachtungen im folgenden Diagramm.
Berechnen Sie die folgenden Größen und geben Sie die Antwort auf mindestens zwei Nachkommastellen gerundet an (kein Bruch)!
F(15)=
Der Median x_\text{med}=
f(30)=
Das arithmetische Mittel \overline{x}=
h(0)=
Die Spannweite R=
F(15)=0.55
Der Median x_\text{med}=10
f(30)=0.3
Das arithmetische Mittel \overline{x}=11.25
h(0)=1
Die Spannweite R=40
Gegeben ist die empirische Verteilungsfunktion F(x) von 25 Beobachtungen im folgenden Diagramm.
h(-8)=
H(4.9)=
f(0)=
F(5.2)=
Der Median x_\text{med}=
Die Spannweite R=
Das arithmetische Mittel \overline{x}=
h(-8)= 2
H(4.9)= 10
f(0)= 0.2
F(5.2)= 0.4
Der Median x_\text{med}= 9
Die Spannweite R= 38
Das arithmetische Mittel \overline{x}= 8
Gegeben ist die empirische Verteilungsfunktion F(x) von 20 Beobachtungen im folgenden Diagramm.
h(160)=
H(130)=
f(40)=
F(240)=
Der Median x_\text{med}=
Die Spannweite R=
Das arithmetische Mittel \overline{x}=
h(160)= 3
H(130)= 6
f(40)= 0.2
F(240)= 0.45
Der Median x_\text{med}= 270
Die Spannweite R= 390
Das arithmetische Mittel \overline{x}= 212.5
Gegeben ist die empirische Verteilungsfunktion F(x) von 20 Beobachtungen im folgenden Diagramm.
h(0.005)=
H(0.23)=
f(0.021)=
F(0.071)=
Der Median x_\text{med}=
Die Spannweite R=
Das arithmetische Mittel \overline{x}=
h(0.005)= 6
H(0.23)= 20
f(0.021)= 0.1
F(0.071)= 1
Der Median x_\text{med}= 0.005
Die Spannweite R= 0.039
Das arithmetische Mittel \overline{x}= 0.0062
Gegeben ist die empirische Verteilungsfunktion F(x) von 20 Beobachtungen im folgenden Diagramm.
h(1500)=
H(2600)=
f(4600)=
F(4800)=
Der Median x_\text{med}=
Die Spannweite R=
Das arithmetische Mittel \overline{x}=
h(1500)= 0
H(2600)= 5
f(4600)= 0.25
F(4800)= 0.95
Der Median x_\text{med}= 3500
Die Spannweite R= 3200
Das arithmetische Mittel \overline{x}= 3550
Gegeben ist die empirische Verteilungsfunktion F(x) von 40 Beobachtungen im folgenden Diagramm.
Berechnen Sie die folgenden Größen und geben Sie die Antwort auf mindestens zwei Nachkommastellen gerundet an (kein Bruch)!
Die Spannweite R=
Das arithmetische Mittel \overline{x}=
F(14)=
Der Median x_\text{med}=
h(20)=
H(1)=
Die Spannweite R=35
Das arithmetische Mittel \overline{x}=15
F(14)=0.475
Der Median x_\text{med}=20
h(20)=3
H(1)=11
Gegeben ist die empirische Verteilungsfunktion F(x) von 40 Beobachtungen im folgenden Diagramm.
Berechnen Sie die folgenden Größen und geben Sie die Antwort auf mindestens zwei Nachkommastellen gerundet an (kein Bruch)!
Die Spannweite R=
H(15)=
F(13)=
Der Median x_\text{med}=
Das arithmetische Mittel \overline{x}=
h(0)=
Die Spannweite R=40
H(15)=24
F(13)=0.6
Der Median x_\text{med}=10
Das arithmetische Mittel \overline{x}=10.375
h(0)=5
Gegeben ist die empirische Verteilungsfunktion F(x) von 25 Beobachtungen im folgenden Diagramm.
Berechnen Sie die folgenden Größen und geben Sie die Antwort auf mindestens zwei Nachkommastellen gerundet an (kein Bruch)!
f(0)=
Das arithmetische Mittel \overline{x}=
H(-2)=
Der Median x_\text{med}=
Die Spannweite R=
F(2)=
f(0)=0.2
Das arithmetische Mittel \overline{x}=13.2
H(-2)=3
Der Median x_\text{med}=10
Die Spannweite R=35
F(2)=0.32
Gegeben ist die empirische Verteilungsfunktion F(x) von 50 Beobachtungen im folgenden Diagramm.