Wir wollen in diesem Kapitel keine sehr ausführlichen Überblick über alle möglichen Grafiken geben. Eine kleine Einführung ist im Skript Wirtschaftsmathematik Grafiken erstellen und einige Beispiel sind im Merkmale und dem EDA zu finden.
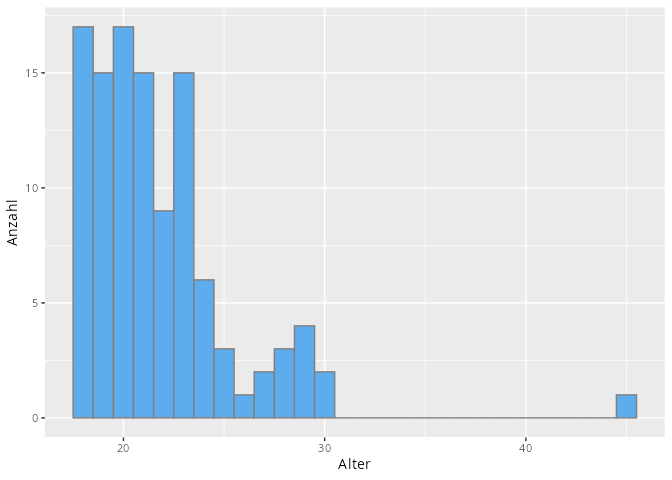
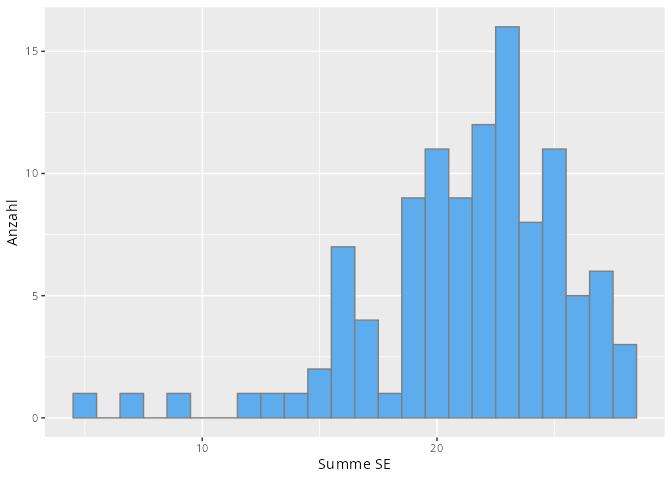
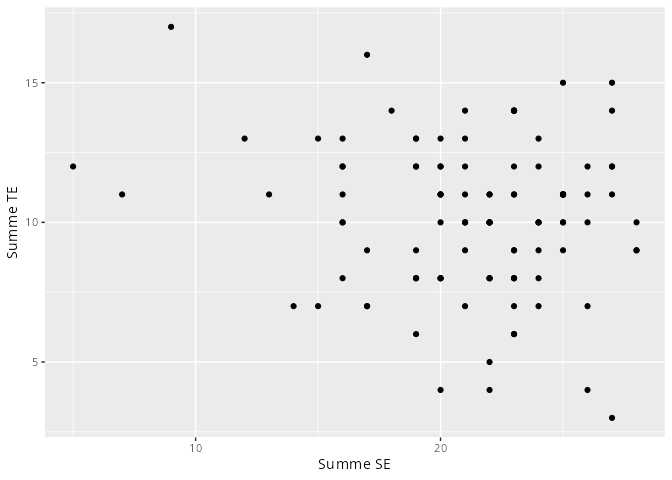
Die einfachste und beste Grafik für univariate Daten sind Histogramme. In unserem Beispiel können wir zum Beispiel das Alter oder die Summenwerte eines Konstrukts jeweils in einem Histogramm darstellen.
umfrage|>ggplot(aes(x =Alter))+geom_histogram(binwidth =1, fill ="steelblue2", color ="grey50")+labs(y ="Anzahl")
umfrage|>ggplot(aes(x =Summe_SE))+geom_histogram(binwidth =1, fill ="steelblue2", color ="grey50")+labs(x ="Summe SE", y ="Anzahl")
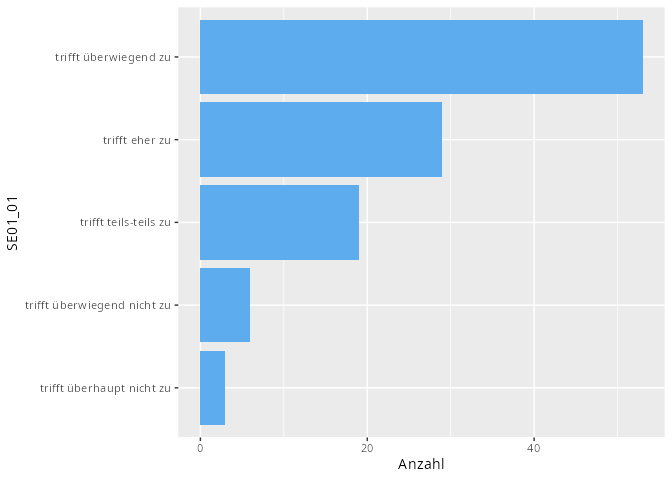
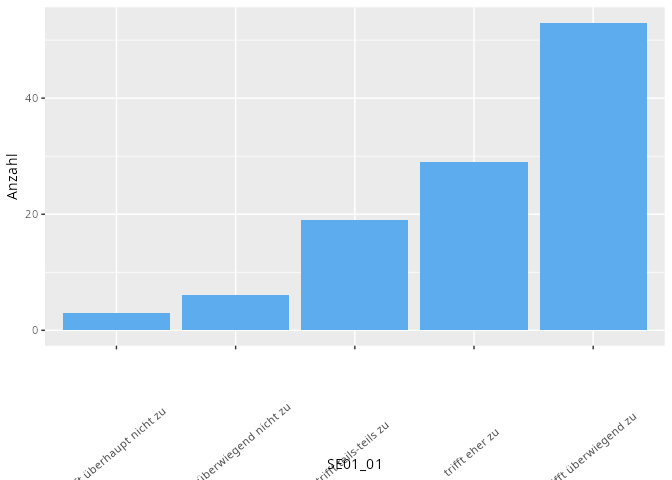
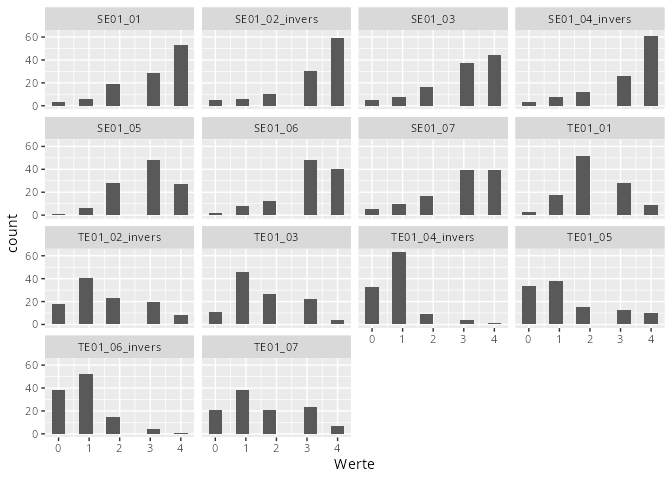
Univariate, kategoriale Daten werden als Balken- oder Säulendiagramm dargestellt. In unserem Beispiel können wir zum Beispiel die Antworten eines Items bevor diese zu einem metrischen Merkmal konvertiert wurden
Mit dem Mosaikplot erkennt man sowohl die Verteilung der einzelnen Merkmale als auch die Verteilung des zweiten Merkmals (y-Achse) gegeben die Ausprägung des ersten Merkmals (sog. bedingten Wahrscheinlichkeiten).
WichtigBemerkung: (Stand: April 2026)
Derzeit ist das Paket ggmosaic nur direkt von github installierbar, da eine Version, die mit ggplot 4.0 verträglich ist noch nicht im CRAN eingecheckt ist.
Um die Unabhängigkeit zweier kategorialer Merkmale zu prüfen, ist der Mosaikplot aus dem Paket ggmosaic die richtige Wahl.
4.3 Pivotieren
Das Konzept des Pivotierens gehört eigentlich in die Datenaufarbeitung, allerdings benötigen wir es insbesondere um Daten facettiert darstellen zu können: Wir wollen nun alle Items gleichzeitig in facettierten Histogrammen darstellen. Das Problem ist nun, dass jedes Item ein eigenes Merkmal ist. Die Idee ist, dass man alle Werte in ein Merkmal schreibt und den Namen des zugehörigen Merkmals in ein anderes Merkmal schreibt. Man macht also aus einer breiten eine lange Tabelle.