library(readxl)
inverse <- read_excel("dateiname.xlsx",
skip = 0,
n_max = 1
)1 Daten einlesen
Nachdem Daten erhoben wurden, müssen diese exportiert und dann eingelesen werden. Beim Export ist darauf zu achten ein geeignetes Format zu verwenden. Wir wollen uns in diesem Kapitel auf zwei Formate beschränken csv und Excel-Dateien. Diese können mit RStudio direkt eingelesen werden.
1.1 Einlesen von Textdateien
Textdateien sind oft als csv-Dateien gespeichert. Das csv steht für comma-seperated-values, was bedeutet, dass die Merkmale durch Kommata getrennt sind. Da das Komma im Deutschen als Dezimaltrenner dient sind deutschsprachige csv-Dateien oft durch Semikola getrennt.
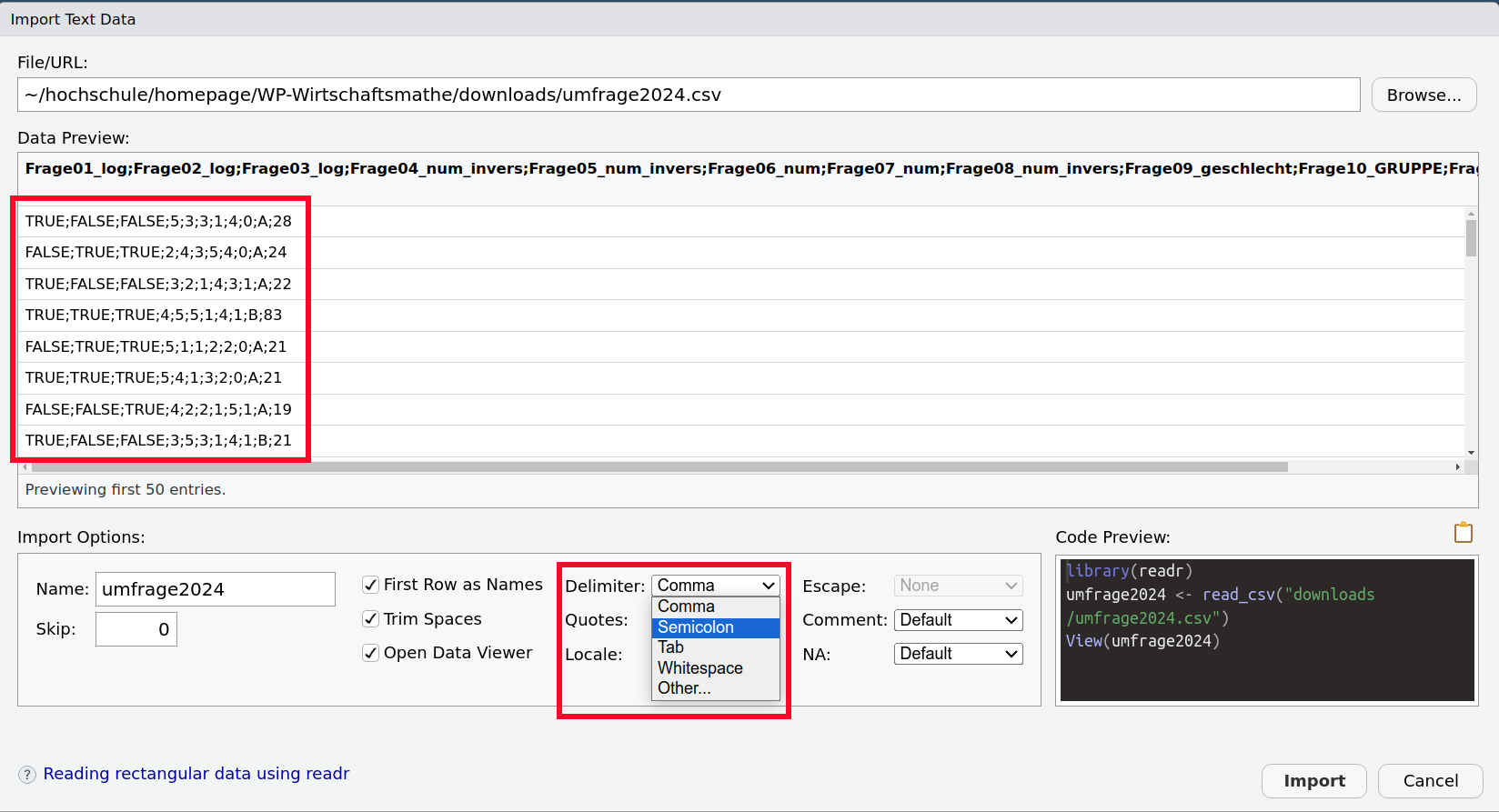
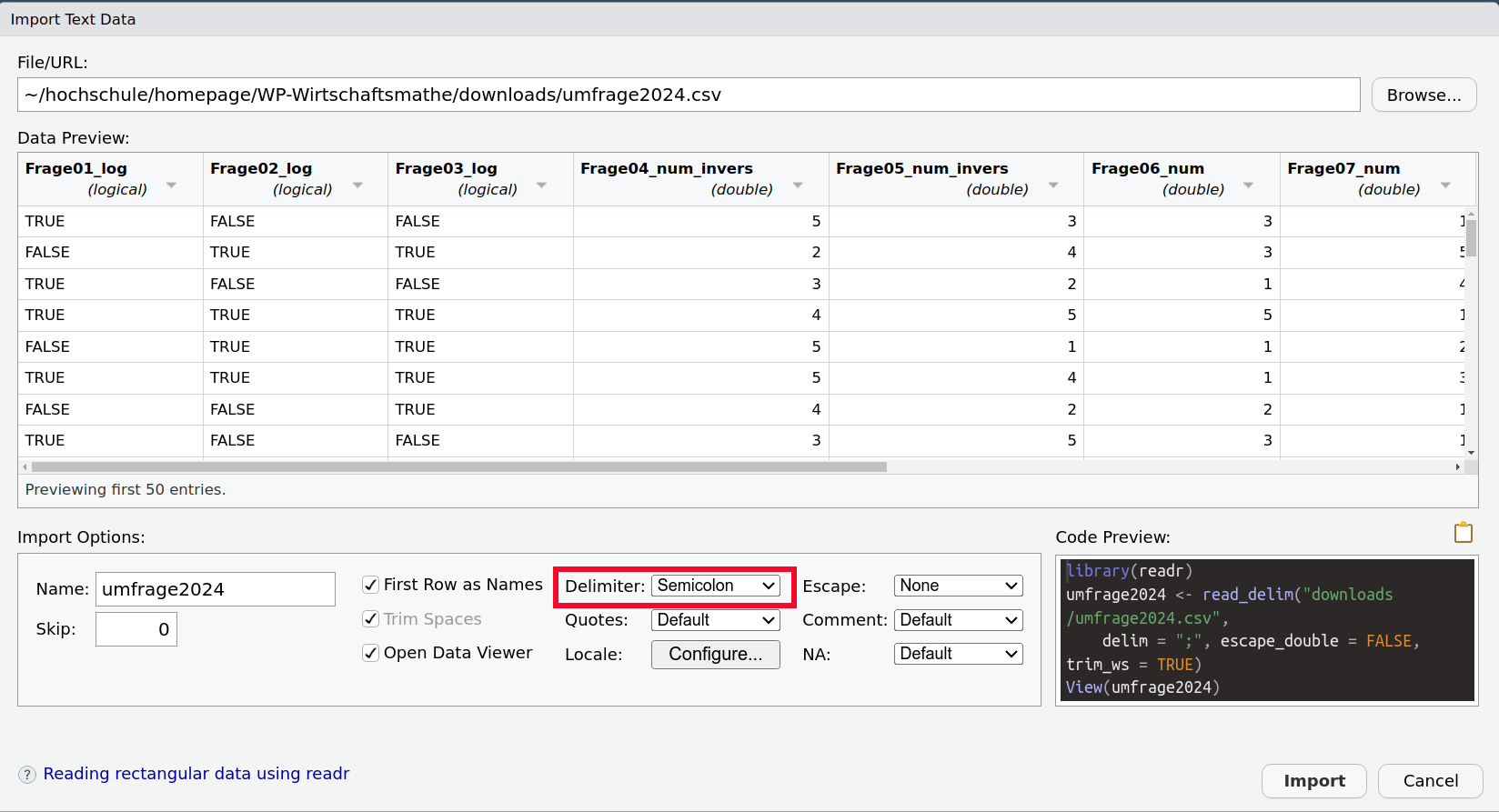
Was kann sonst noch passieren?
Haben die Merkmale keine Namen, so müssen wir den Haken bei First Row as Names entfernen. Es werden dann generische Merkmalsnamen X1, X2, etc. vergeben.
Sind die Merkmalsnamen nicht in der ersten Zeile, sondern erst in einer späteren, so können wir mit Skip angeben wie viele Zeilen ignoriert werden sollen.
1.2 Einlesen von Excel-Dateien
Das Einlesen der Excel-Dateien ist in der Regel unproblematisch. Analog wie bei den Textdateien sucht man das über das Menu Import Dataset >> From Excel >> Browse… die zu installierende Datei aus.
Danach muss sichergestellt werden, dass
- das richtige Sheet eingelesen wird,
- die Merkmalsnamen erkannt werden. Gegebenenfalls müssen mit Skip Zeilen übersprungen werden. Sollten keine Merkmalsnamen existieren, so muss der Haken bei First Row as Names entfernt werden und es werden generische Namen vergeben.
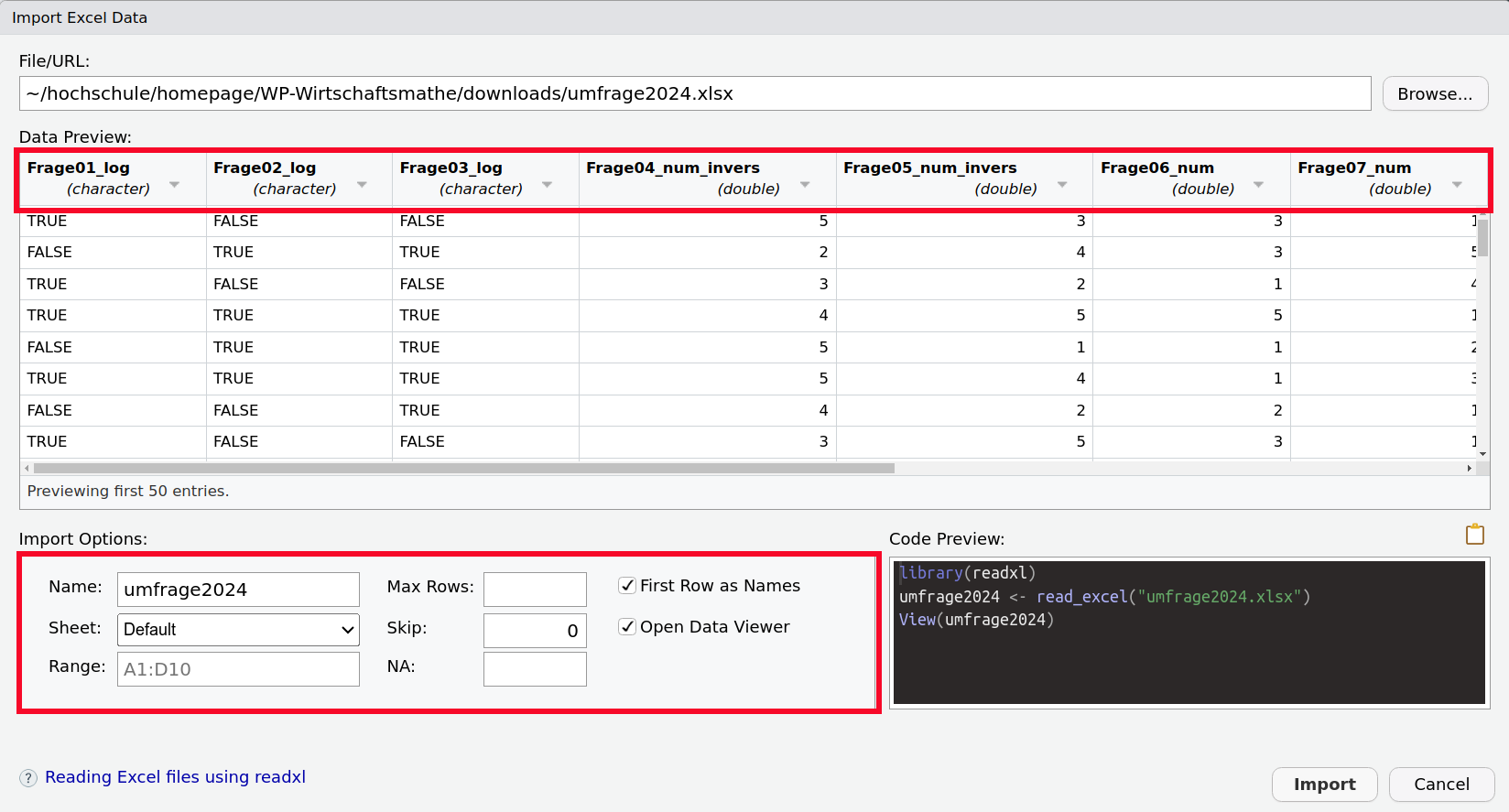
Bemerkungen: Einlesen mittels Skript
- Sowohl in Abbildung 1.3 als auch in Abbildung 1.4 sieht man unten rechts in der Ecke den R-Code.
1.3 Einlesen von Metadaten
In manchen Situationen ist es sinnvoll Informationen bezüglich mancher Merkmale in Zeilen zu kodieren, die nicht Teil des Merkmals sind. Ein Beispiel dafür wäre die Information ob eine Frage invers ist oder nicht. In Abbildung 1.4 ist diese Information im Merkmalsnamen kodiert (_invers), was übrigens für die Auswertung später sehr vorteilhaft ist.
Wie aber gehen wir mit dem folgenden Datensatz um?
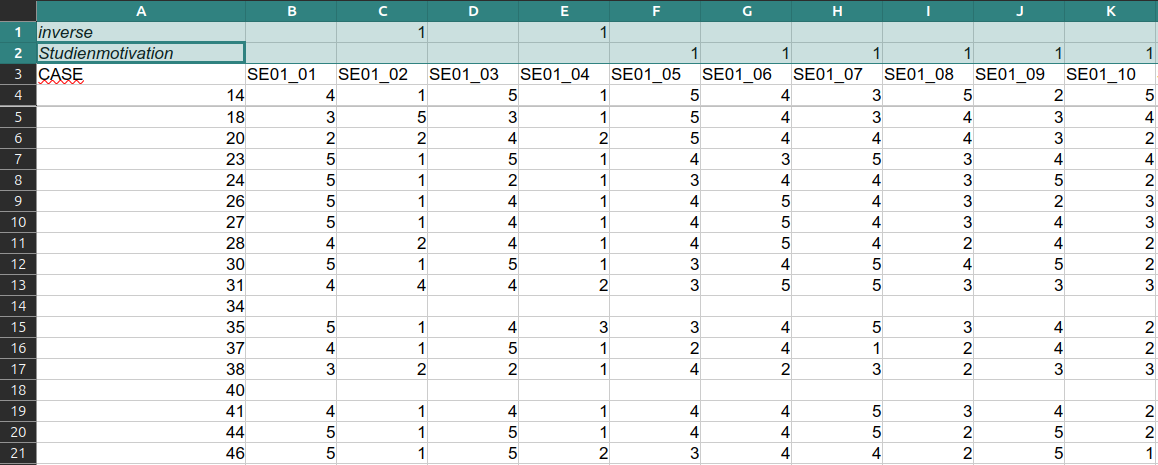
Die geeignete Methode ist das Einlesen mit den Tidyverse-Pakten readrfür csv-Datein bzw. readxl für Exceldateien. Die Syntax ist bei beiden gleich. Wollen wir beispielsweise aus dem in Abbildung 1.5 dargestellten Datensatz die erste Zeile einlesen, so geschieht dies wie folgt:
Das Argument n_max=1 bedeutet, dass exakt eine Zeile eingelesen wird, und skip= gibt an, wie viele Zeilen ausgelassen werden müssen.